
Cracking the Go Concurrency Basics - Part 1
Part of the Go-In-Depth-Series, this time on concurrency, parallelism, goroutines and data synchronisation


This week’s newsletter aims to approach the basics of Go concurrency by going through a couple of concepts:
the difference between concurrency and parallelism
how different concepts are done in the JVM (Java) vs Go
how goroutines are scheduled
ways of declaring goroutines
ways of synchronising goroutines by going through the different sync package primitives
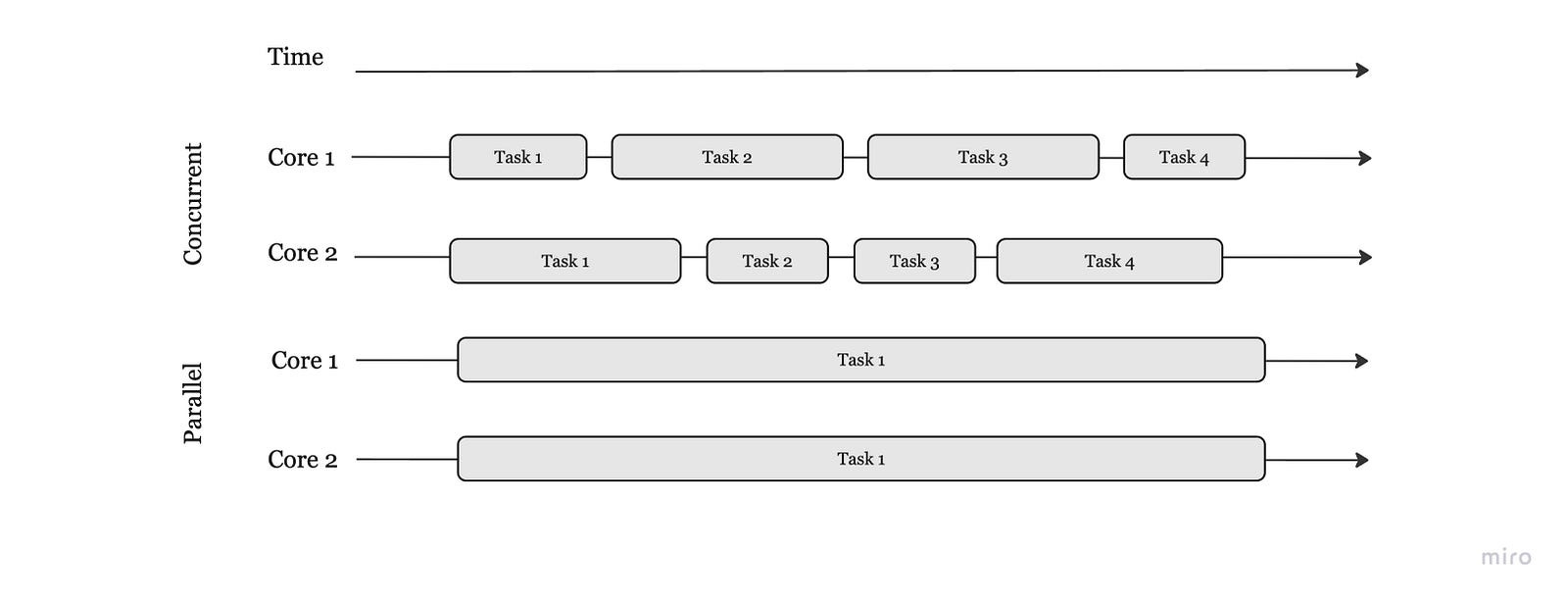
Concurrency vs Parallelism
“Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.” — Rob Pike
Concurrency is a property of the code; parallelism is a property of the running program.
Concurrency is a semantic property of a program or system. Concurrency is when multiple tasks are in progress for overlapping periods of time. Concurrency is a conceptual property of a program or a system, it’s more about how the program or system has been designed. Long story short, concurrency happens when you have context switching between sequential tasks.
Using the same example as Kirill Bobrov uses in Grokking Concurrency, imagine that one cook is chopping salad while occasionally stirring the soup on the stove. He has to stop chopping, check the stove top, and then start chopping again, and repeat this process until everything is done.
As you can see, we only have one processing resource here, the chef, and his concurrency is mostly related to logistics; without concurrency, the chef has to wait until the soup on the stove is ready to chop the salad.
Parallelism is an implementation property. It resides on the hardware layer.
Parallelism is about multiple tasks or subtasks of the same task that literally run at the same time on a hardware with multiple computing resources like multi-core processor.
Back in the kitchen, now we have two chefs, one who can do stirring and one who can chop the salad. We’ve divided the work by having another processing resource, another chef.
Concurrency can be parallelised but concurrency does not imply parallelism.
e.g. In a single-core CPU, you can have concurrency but not parallelism.
=> We don’t write parallel code, only concurrent code that we hope might be ran in parallel.
What are GoRoutines?
GoRoutines are light-weight execution threads integrated into Go’s runtime that run independently, along with the initialised functions.
Concurrency in Go vs Java
Scheduling
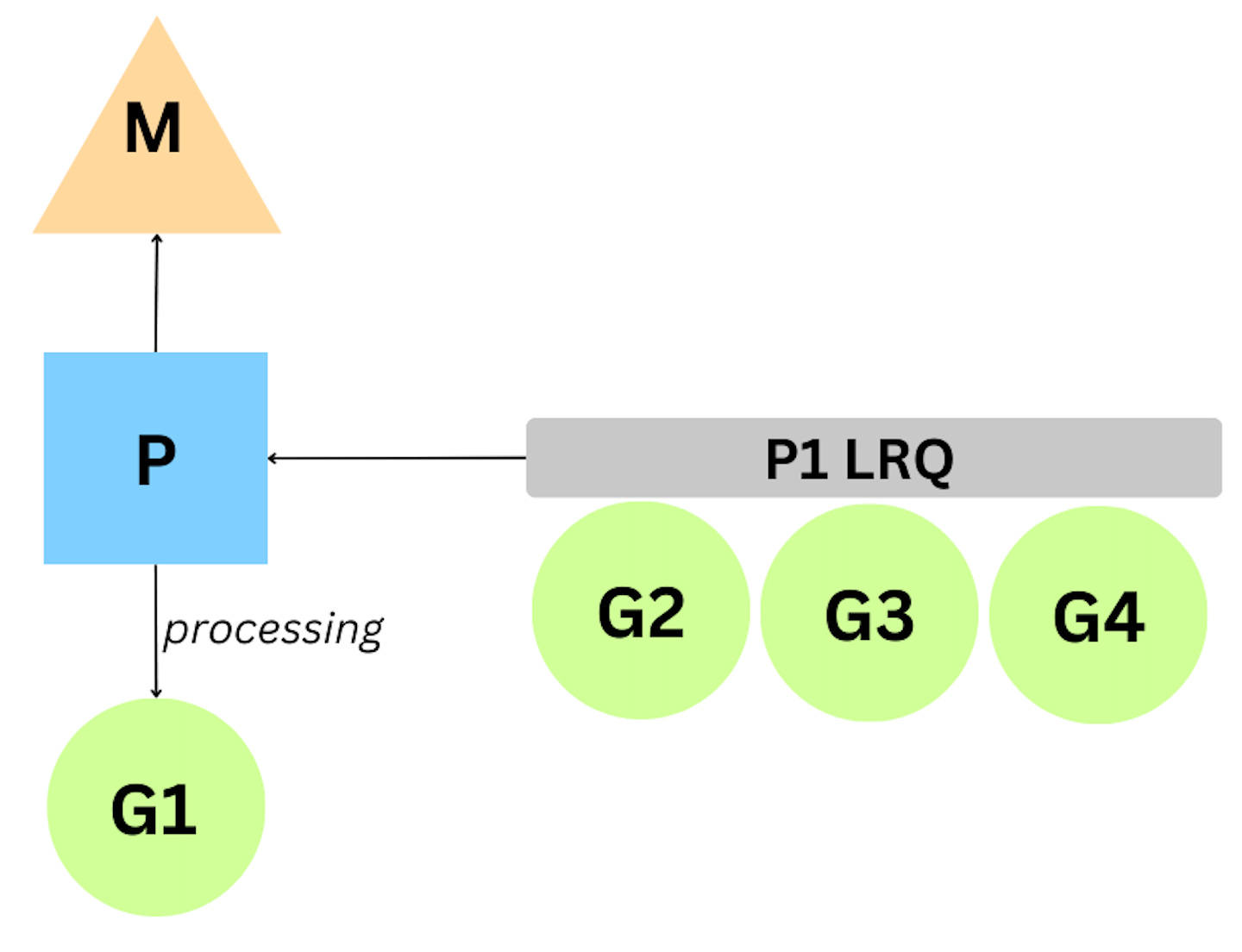
Go’s mechanism for hosting goroutines is an implementation of what’s called an M:N scheduler: which states that M number of goroutines can be distributed over N number of OS threads.

When a Go program starts => it is given a logical processor P for every virtual core => Every P is assigned an OS thread M => Every Go program is also given an initial G which is the path of execution for a Go program. OS threads are context-switched on and off a core, goroutines are context-switched on and off a M.
There are two run queues in the Go scheduler.
Global Run Queue (GRQ)
Local Run Queue (LRQ)
Each P is given given a LRQ that manages the goroutines assigned to be executed within the context of P. These goroutines take turn being context-switched on and off the M assigned to that P. GRQ is for goroutines that have not been assigned to a P yet.
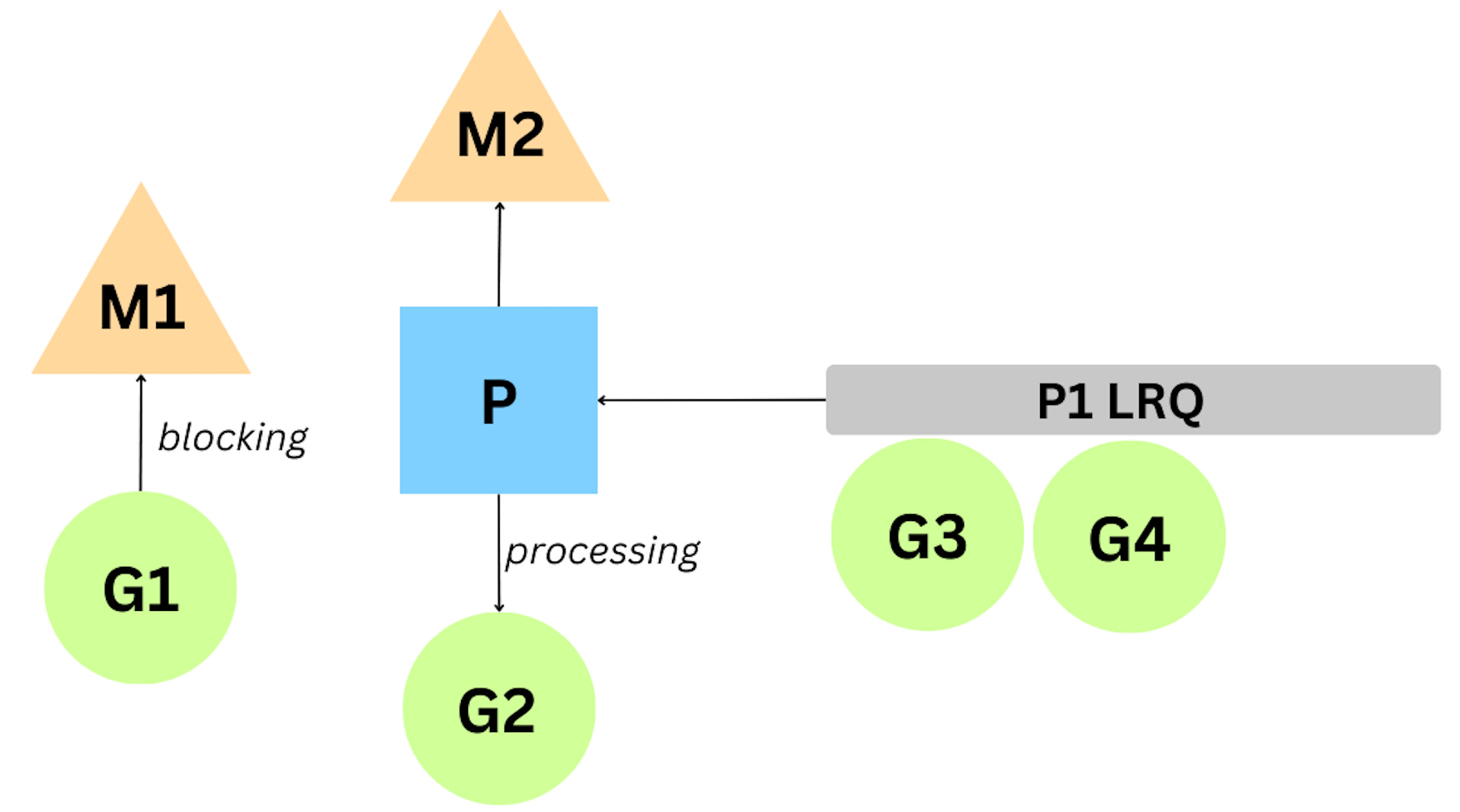
When a goroutine is performing an asynchronous system call, P can swap the G off M and put in a different G for execution. However, when a goroutine is performing a synchronous system call, the OS thread is effectively blocked. Go scheduler will create a new thread to continue servicing the existing goroutines in the LRQ.
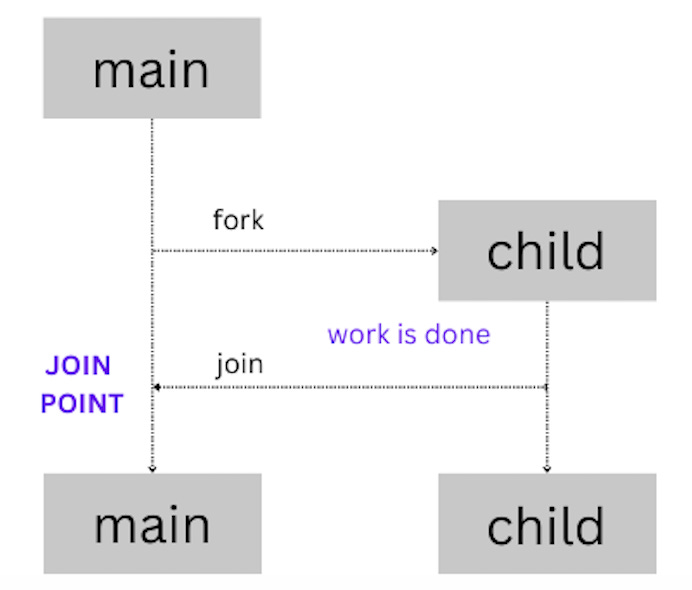
Go follows a model of concurrency called the fork-join model:
fork — at any point in the program, a child branch of execution can be split off and run concurrently with its parent
join — at some point in the future, the concurrent branches of execution will join back together
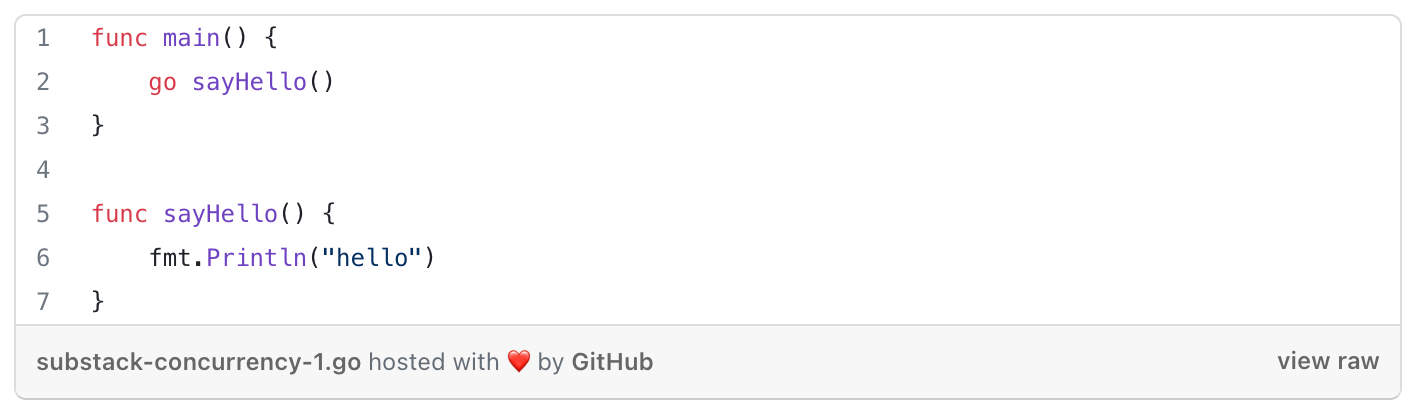
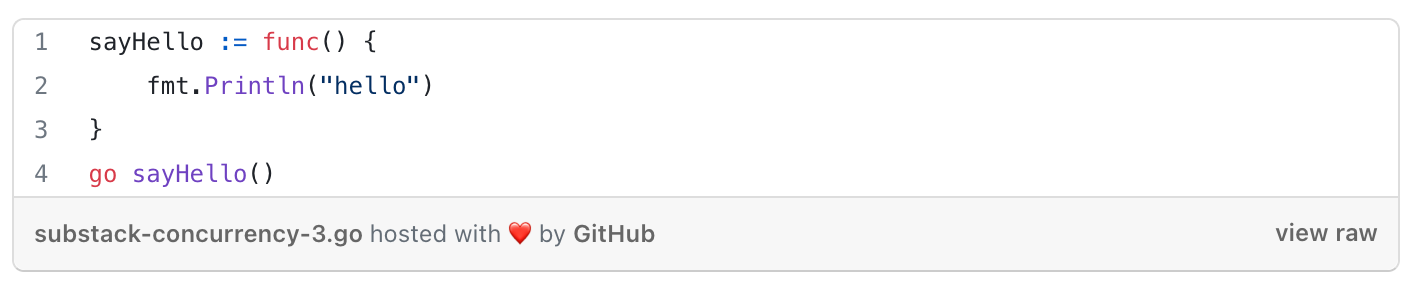
Ways of declaring goroutines

Synchronizing goroutines — via sync package
To make sure your goroutines execute before the main goroutine we need join points. These can be created via:
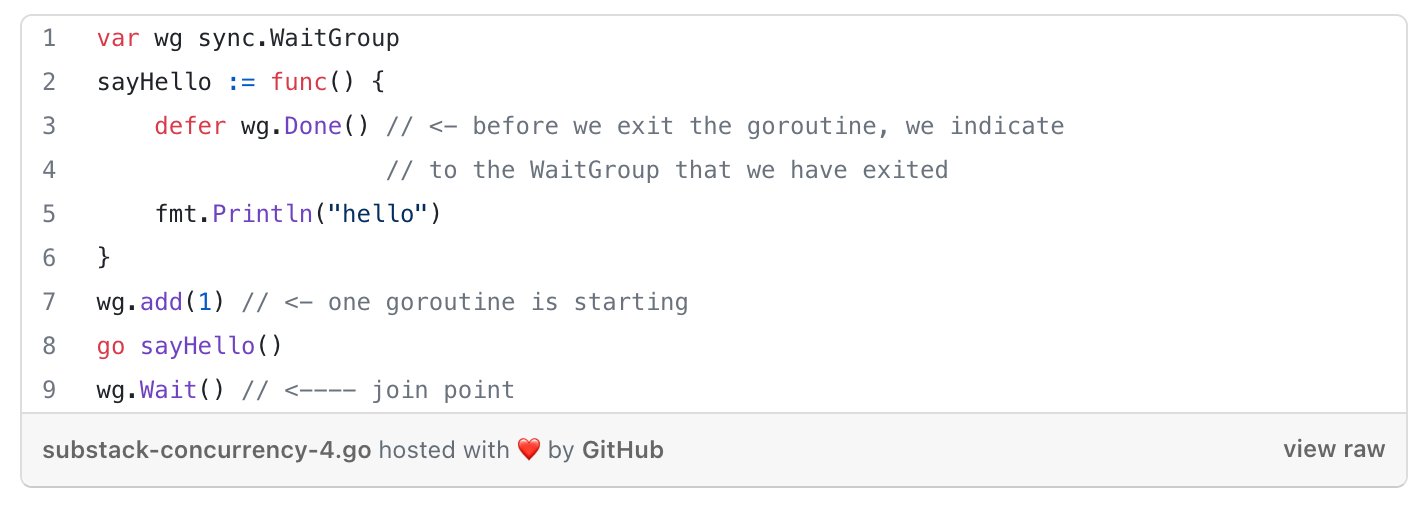
The WaitGroup primitive
used for waiting for a set of concurrent operations to complete when you either don’t care about the result of the concurrent operation, or you have other means of collecting their results.
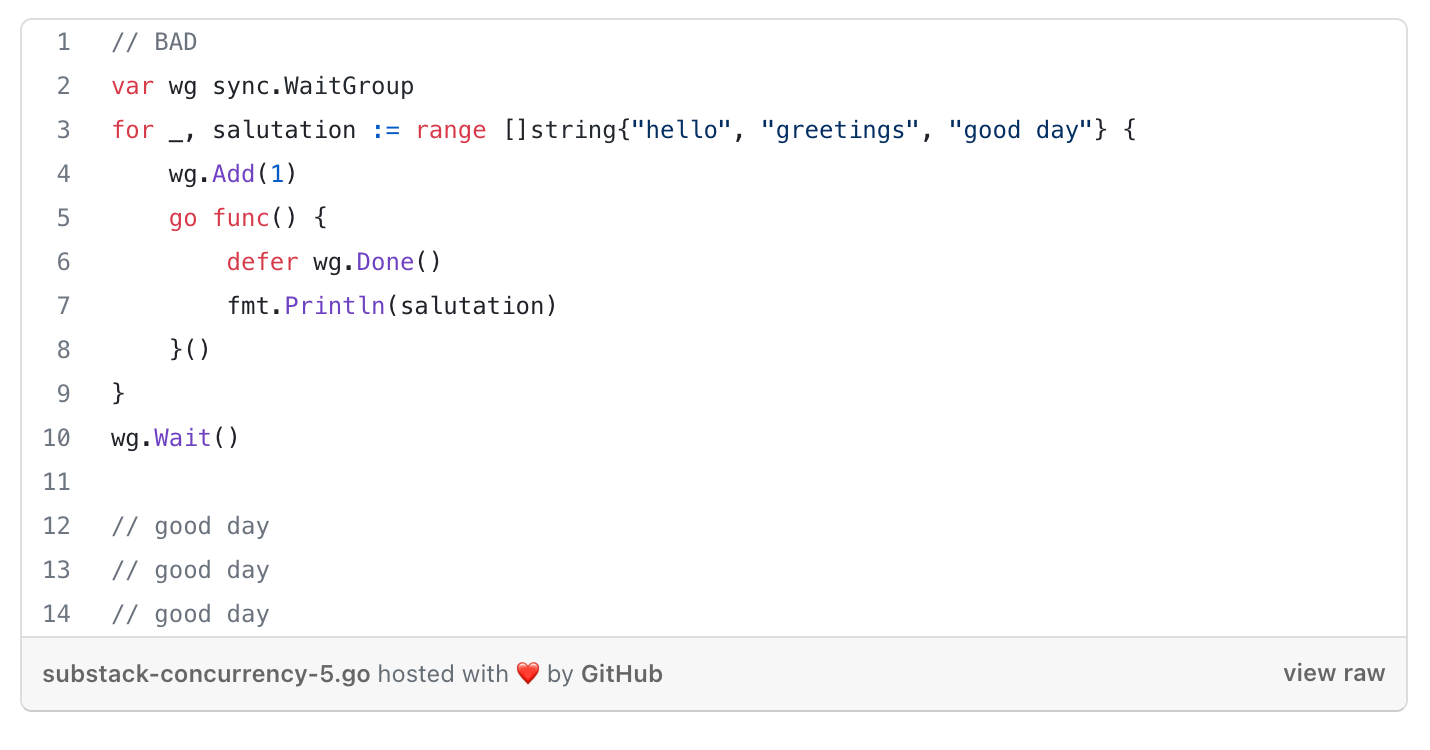
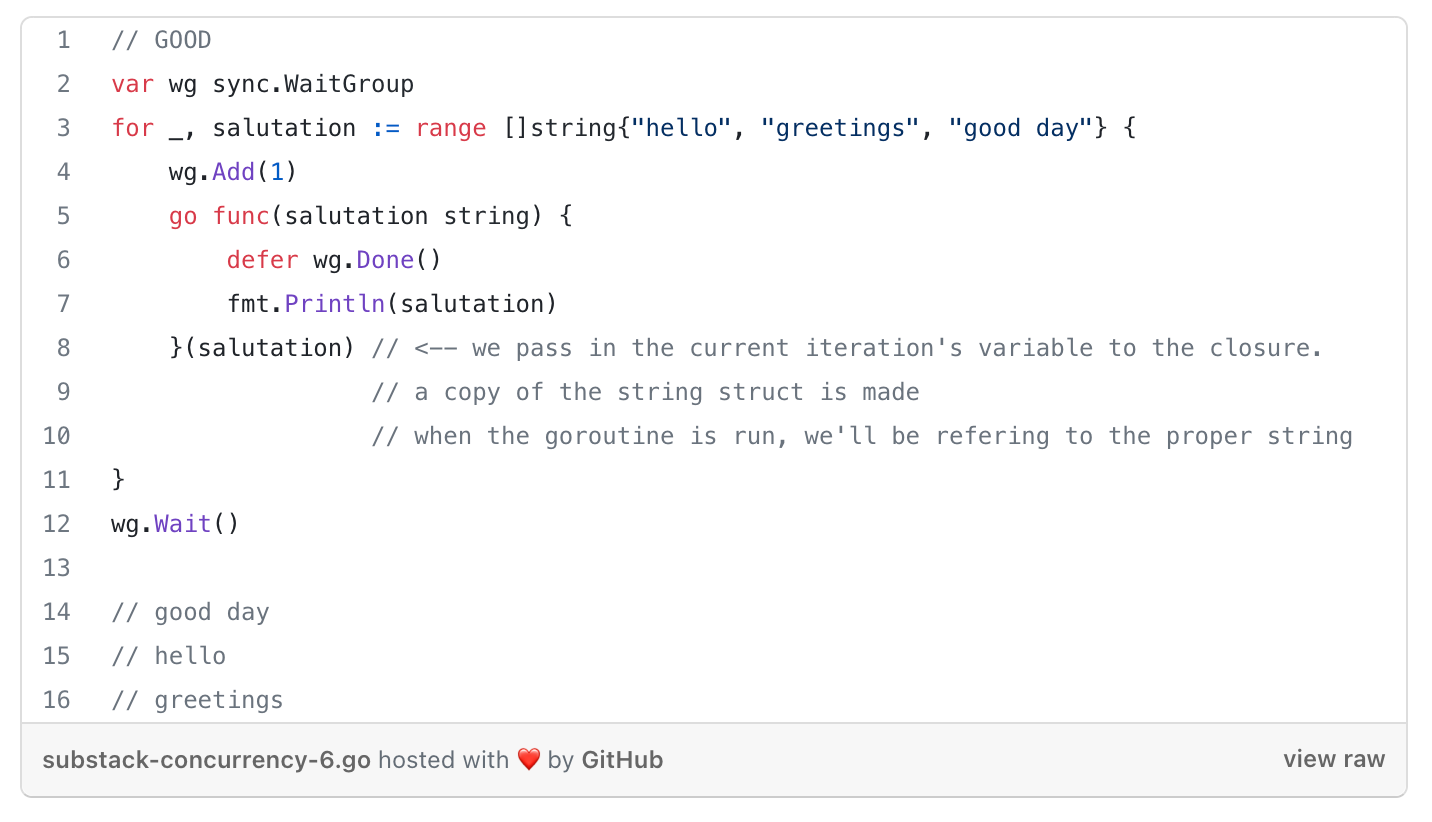
Closures = a function value that references variables from outside its body.
With closures, we’d have to pass a copy of the variable into the closure so by the time a goroutine is run, it will be operating on the data from its iteration of the loop.
The Mutex primitive
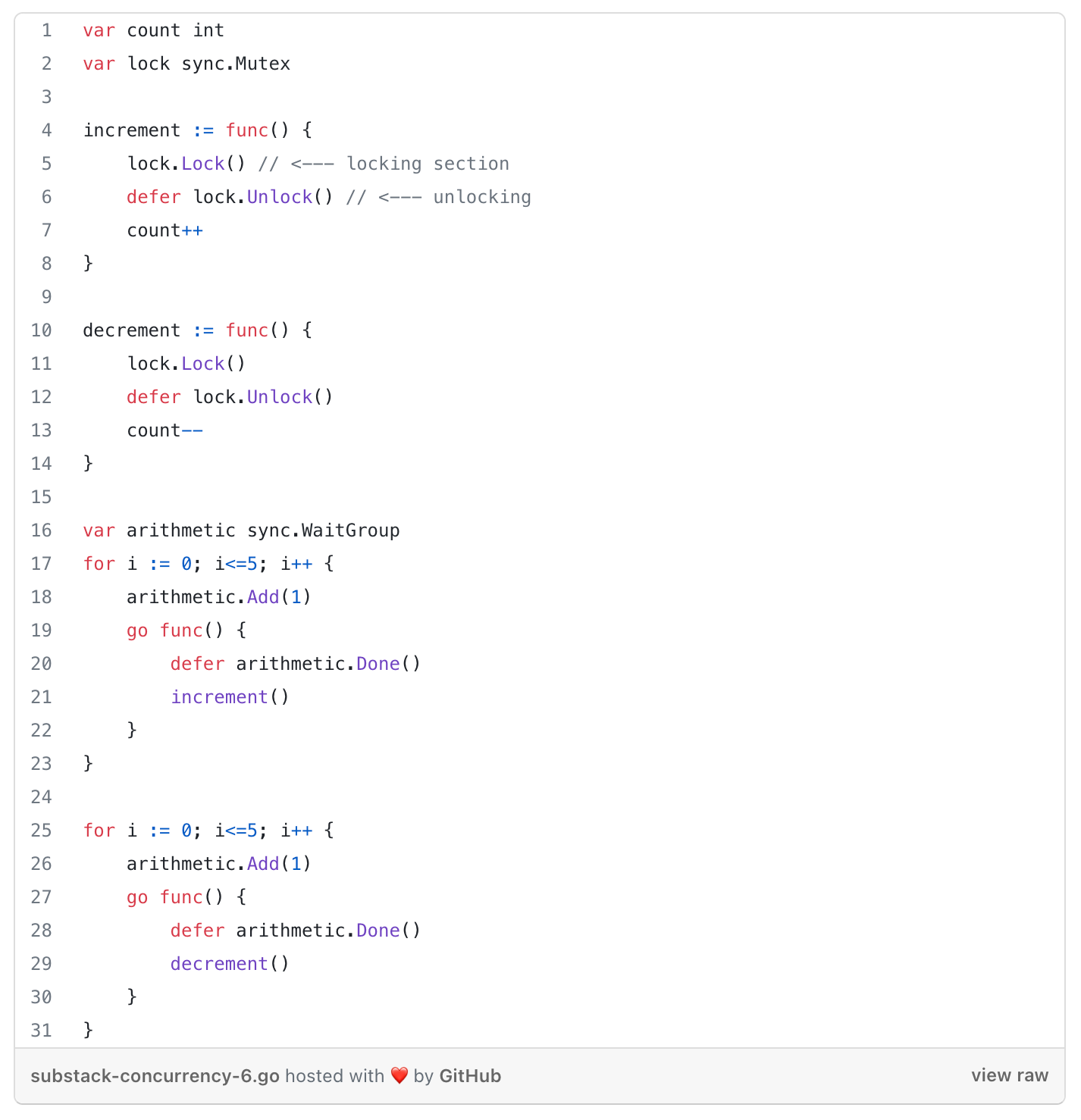
provides a concurrent-safe way to express exclusive access to these shared resources.
How to: sync.Mutex interface with Lock() and Unlock() methods
Shares memory by creating a convention developers must follow to synchronise access to the memory.
The RWMutex primitive
same as Mutex but it provides a read/write lock. We can have a multiple number of readers holding a reader lock as long as nobody is holding a writer lock.
How to: sync.RWMutex interface with RLock() and RUnlock() methods
RWMutex can only be held by n readers at a time, or by a single writer
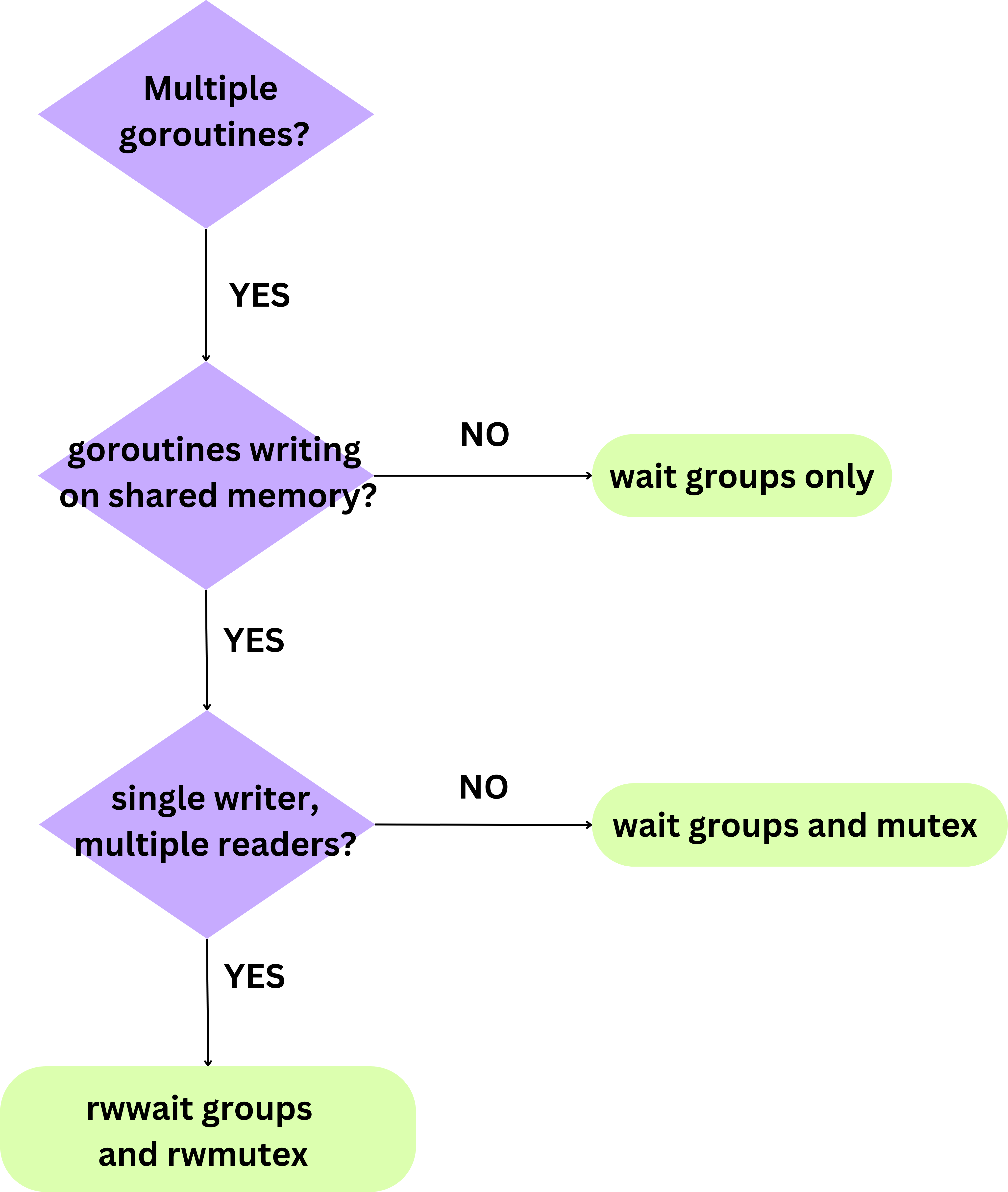
A way of choosing which primitive to use is emphasised in the following diagram:
Other basic primtives
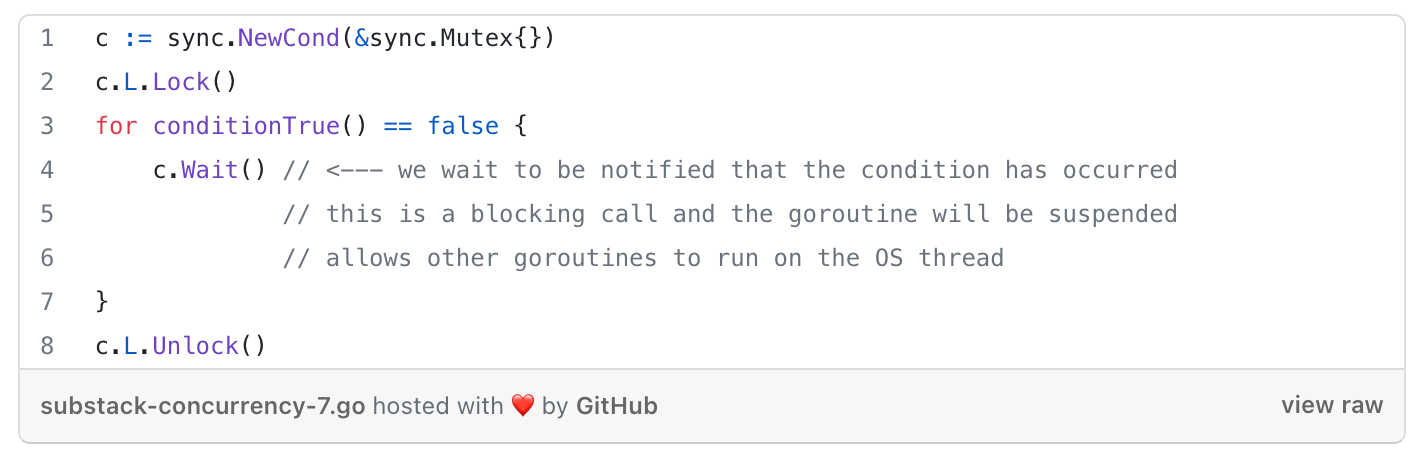
The Cond Primitive
a rendezvous point for goroutines waiting for or announcing the occurrence of an event (=signal between 2 or more goroutines, has no info other than it happened).
How to: sync.NewCond(&sync.Mutex{}) with 2 methods:
Signal - notifies goroutines (runtime picks the one that has been waiting the longest) blocked on a
Waitcall that the condition has been triggered
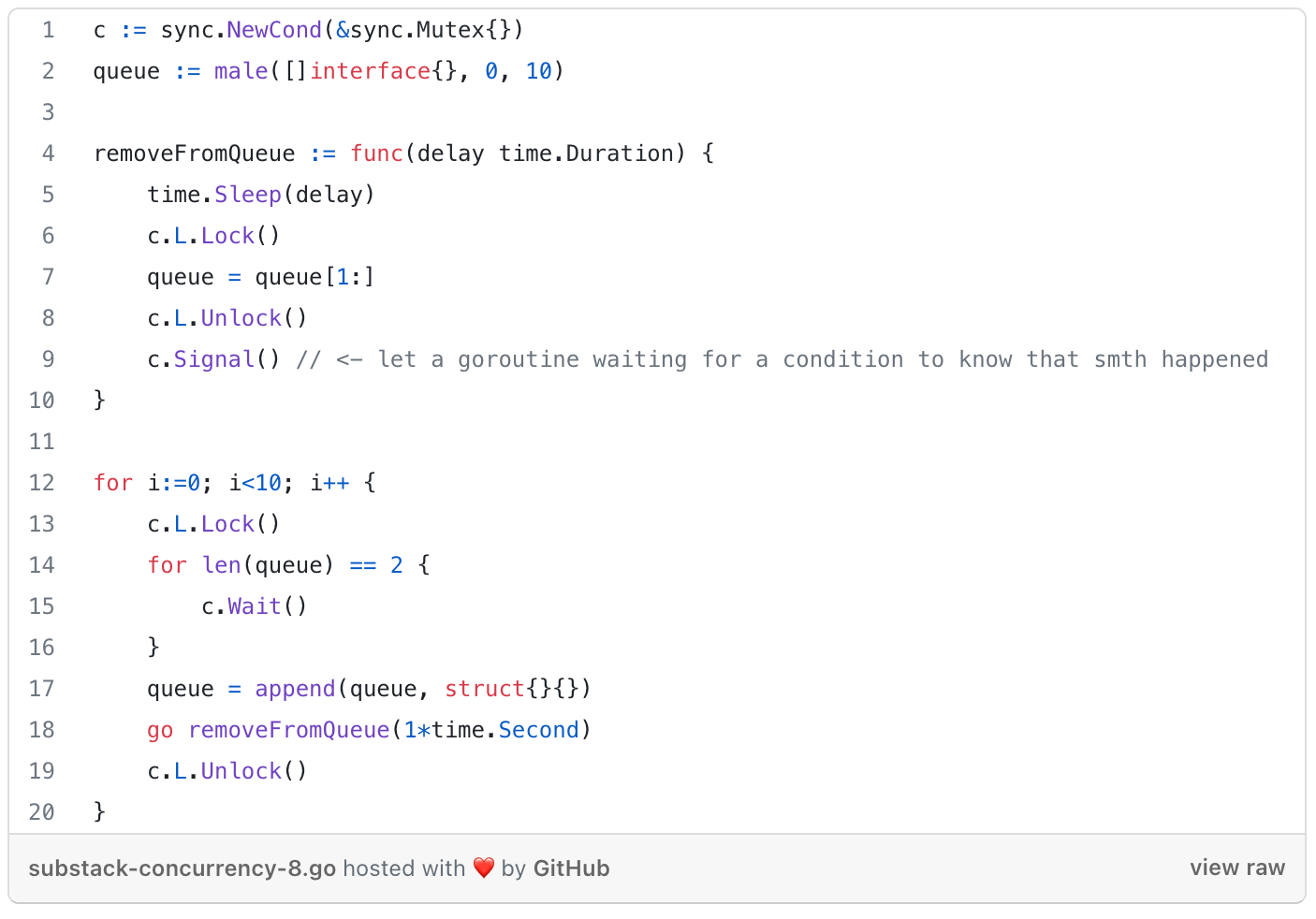
Brodcast - sends signal to all waiting goroutines

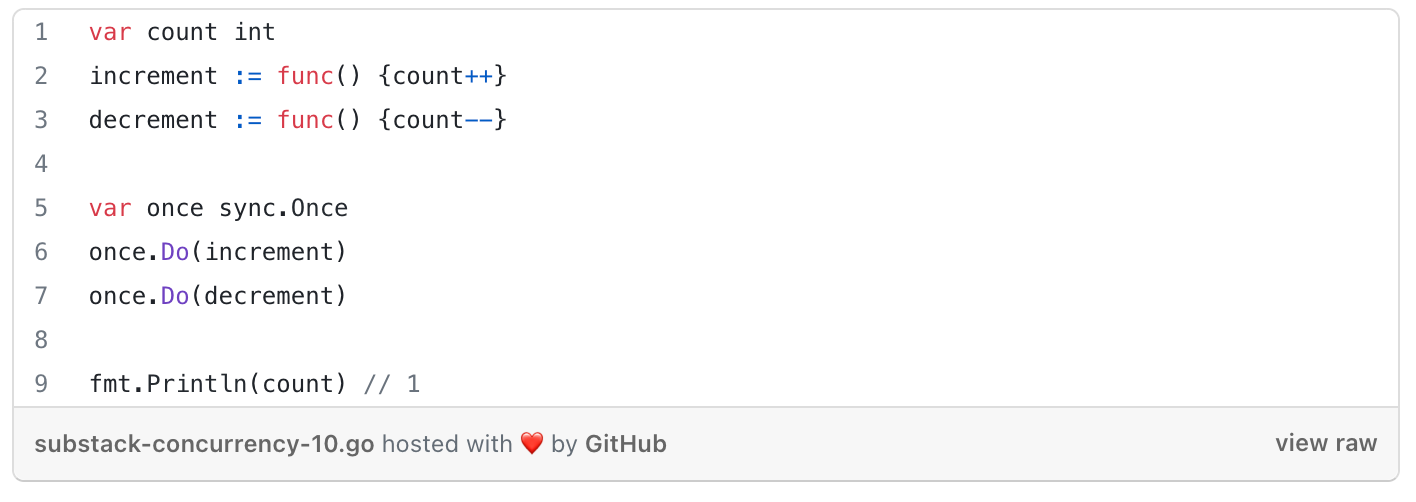
Once
ensures that only one call to Do ever calls the function passed in
counts the no of times
Dois called, not how many unique functions passed intoDoare called
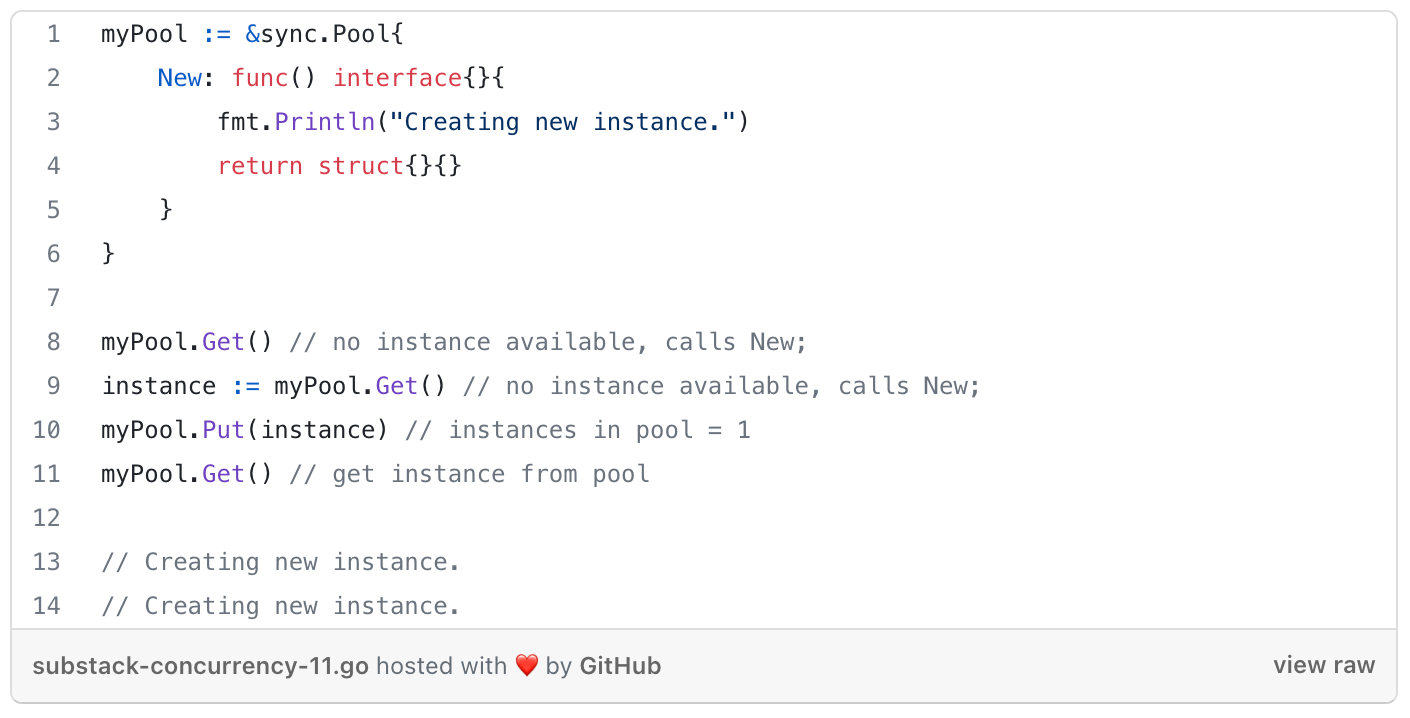
Pool
= concurrent-safe implementation of the object pool pattern.
How to:
Getinterface - checks wether the are any available instances within the pool to return to the caller, and if not, call itsNewmember variable to create one.Putinterface - to put the instance they were working with back in the pool
Uses cases:
memory optimisations as instantiated objects are garbage collected.
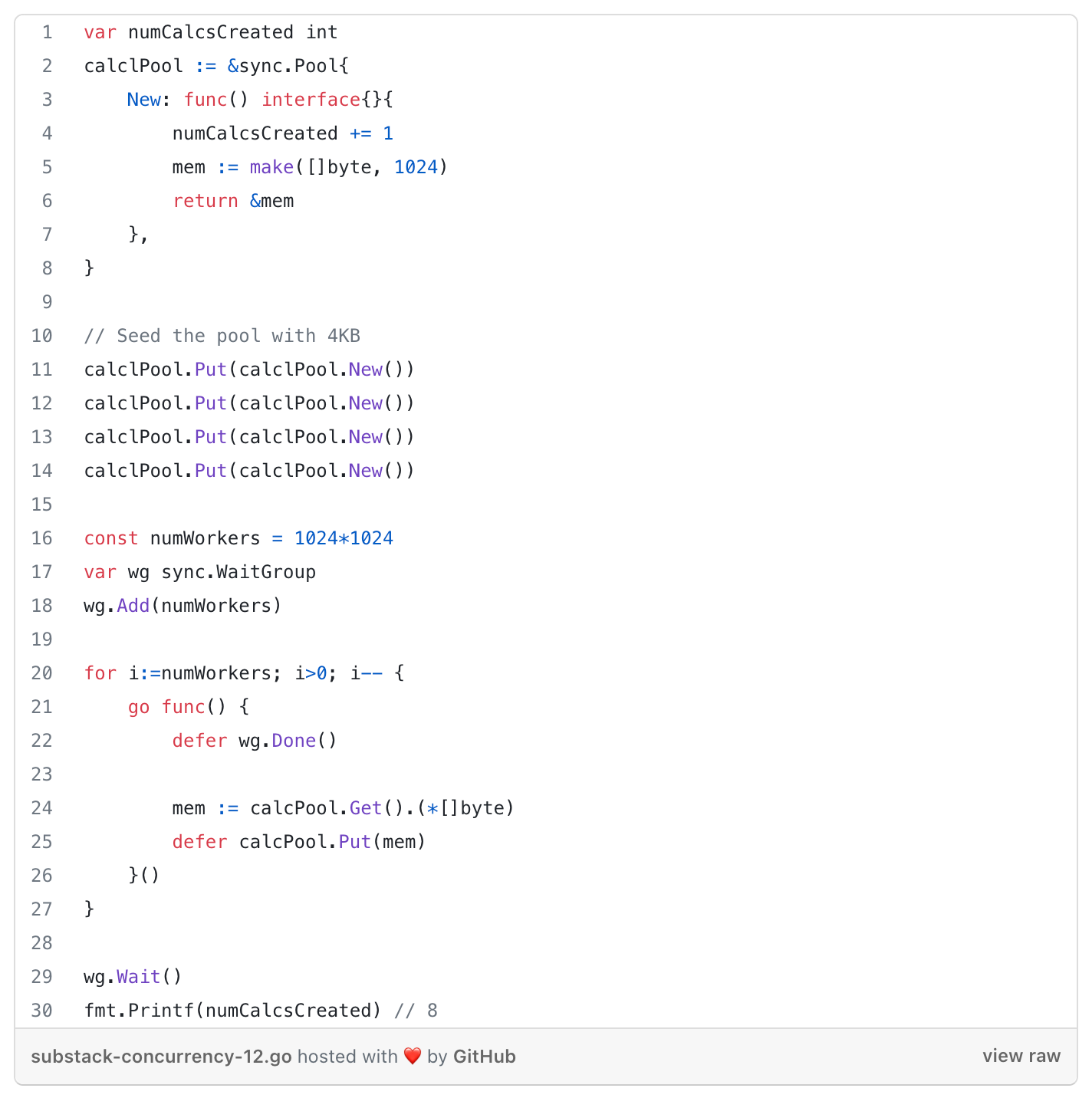
warming up a cache of pre-allocated objects for operations that must run as quickly as possible. (by trying to guard the host machine’s memory front-loading the time it takes to get a reference to another object)

Channels
Can be used to synchronise access of the memory and to communicate information between goroutines.

They support unidirectional flow of data:
channel that can only read

channel that can only send

Sending to/Receiving from a channel
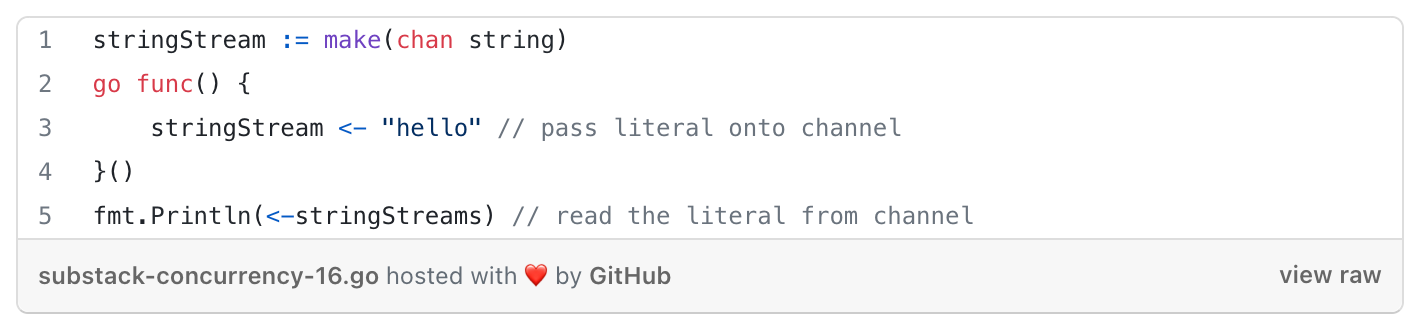
Channels are blocking.
Any goroutine that attempts to write to a channel that is full will wait until the channel has been emptied.
Any goroutine that attempts to read from a channel that is empty will wait until at least one item is placed on it.
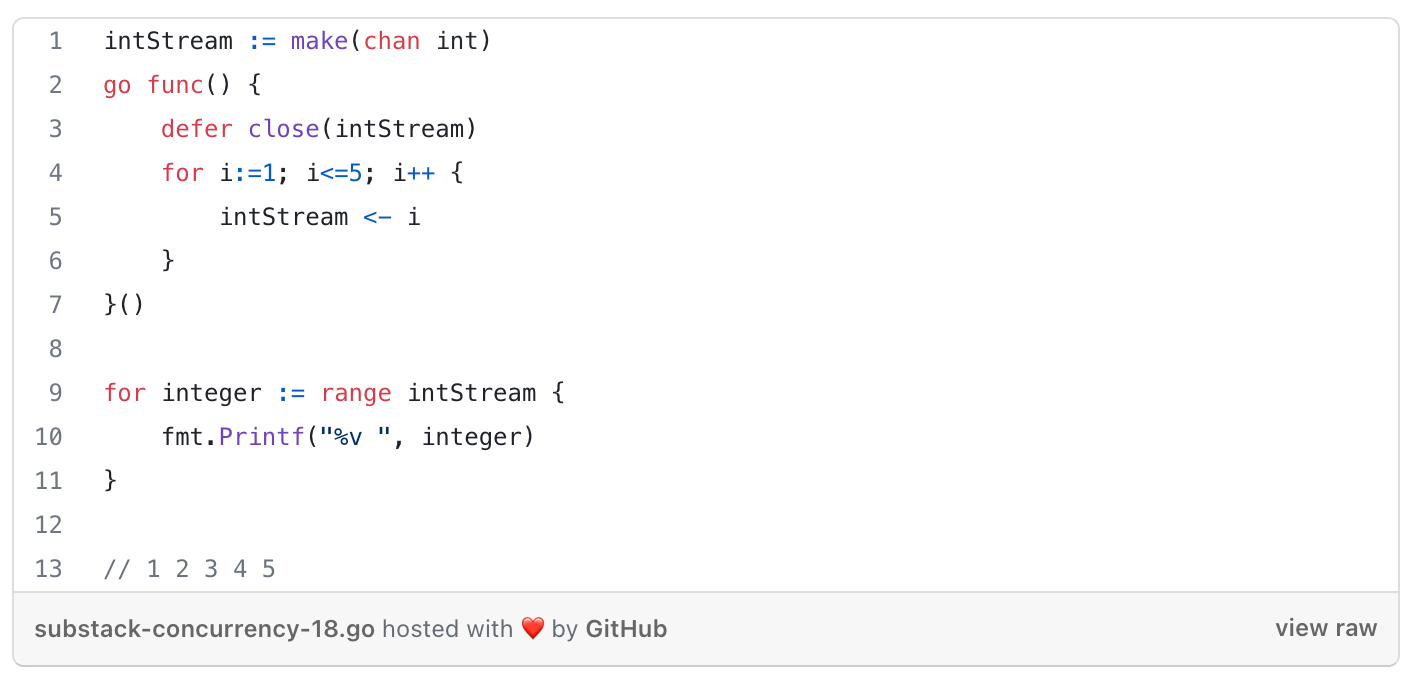
Closing a channel

Ranging over a channel
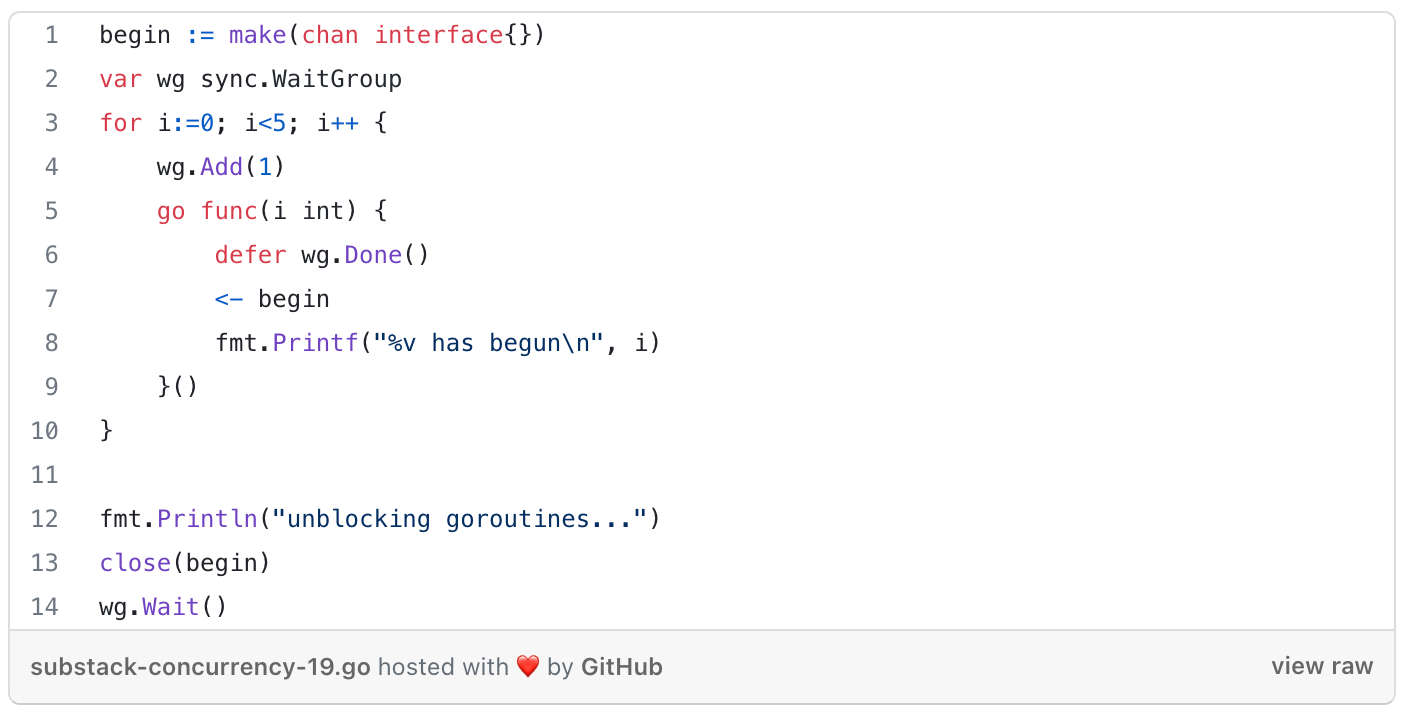
Closing a channel signals to multiple goroutines
Buffered Channels
= channels that are given a capacity when they’re instantiated.

Buffered channels are in-memory FIFO queue for concurrent processes to communicate over.
In the next newsletter, we’ll dive deeper into the result of channel operation given a channel’s state, how to design your code into channel owners and consumers and some other go concurrency patterns.