
Mastering Cache Management: Eviction, Invalidation, and Optimal Data Access Strategies
On caching, what it is, when to use it, benefits, eviction policies, invalidation strategies and read/write flows

A cache is a temporary storage area that improves performance by storing data closer to where it's needed, minimising trips to main storage or external systems. Think of a cache like your browser saving recently visited websites: instead of reloading everything from the internet, it provides a faster experience by using the local copy.
When to use it :
for frequently accessed data - e.g. website assets, session data, popular content
for expensive operations - database queries (if the same complex query is frequently executed), API calls (e.g. weather data, currency conversions), compute intensive calculations
for times when speed is paramount - high-traffic websites (reduce strain on the backend by serving frequent requests), search suggestion (autocomplete features often use a cache to display results instantly as the user types)
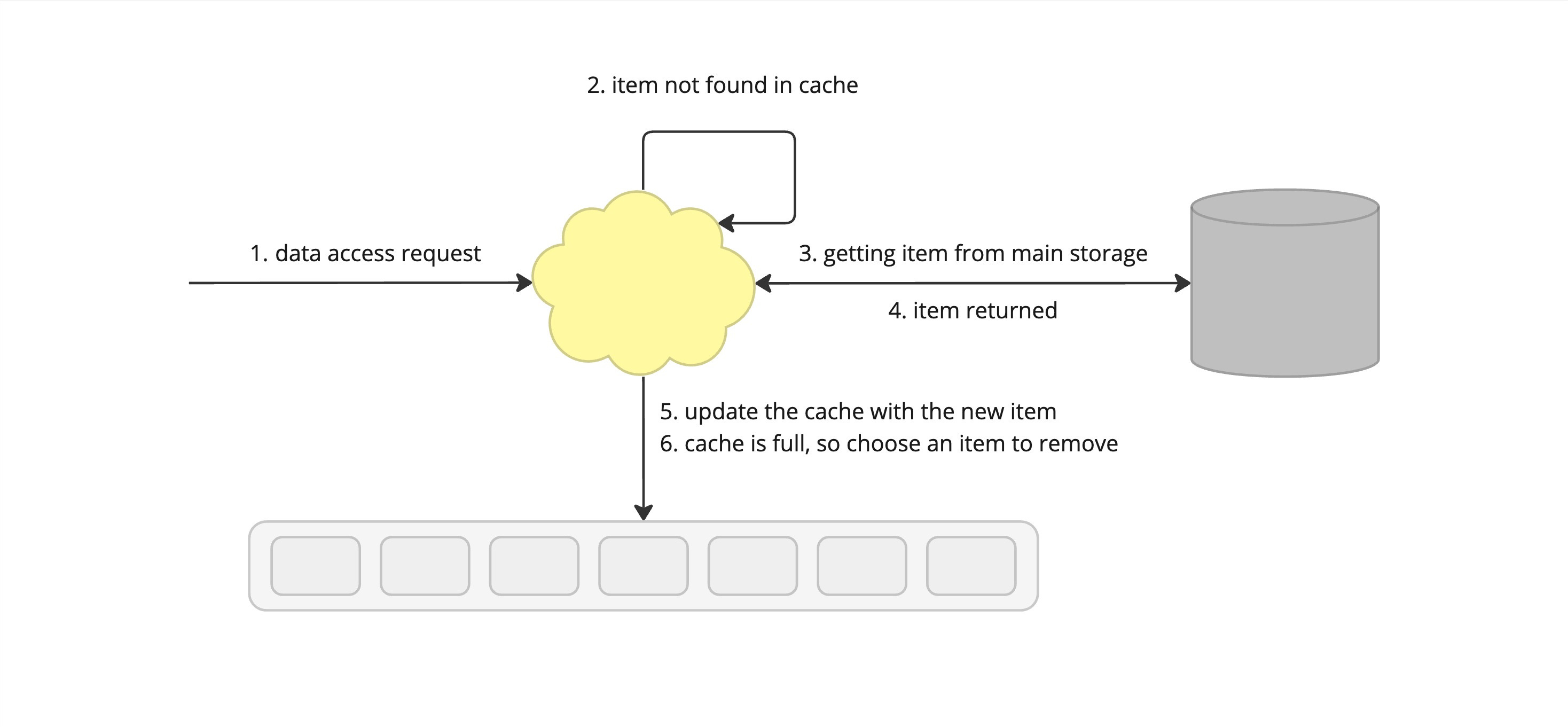
When accessing data from a cache, there's a best-case and a fallback scenario. A cache hit means the data was found in the cache, leading to a speedy response. A cache miss means the data wasn't present, so the system will need to fetch it from the slower main storage.
What to consider:
Amdahl’s Law - “the overall performance improvement gained by optimizing a single part of a system is limited by the fraction of time that the improved part is actually used”
Diminishing Returns: Cache hit rates matter immensely. The initial gains from adding a cache are often dramatic. But, according to Amdahl's Law, as you reach 90, 95, 98% hit rates, the effort to squeeze more performance decreases in effectiveness.
Pareto Distribution - “also known as the “80-20 rule” stating that 80% of outcomes are due to 20% of causes“
Cache Misses Are Not Evenly Distributed: In many systems, some data is far more popular than others. Picture the top 10% of products on an e-commerce site getting 60% of the traffic. This skewed access pattern aligns with the Pareto principle. To get the caching wins, you need to first analyse your data to see if the access patterns truly exhibit Pareto-like characteristics.
Cache Benefits
Faster Access and Reduced Latency - serving data from in-memory stores vs. databases or external APIs offers massive latency gains.
Bandwidth Optimisation - when external API calls or media assets are cached, you can potentially decrease bandwidth usage.
Reduced Database Costs - databases are often a significant cost factor. Offloading queries to a cache can directly lower your database-related expenses.
Improved Throughput - when a cache satisfies a request, your main database or origin servers are untouched. This allows your system to handle more concurrent users without overwhelming core resources.
Handle Spikes - sudden surges that would cripple an uncached system can often be served smoothly when a cache absorbs the brunt of those requests.
Cache Eviction Policies
A caching eviction policy determines how a cache handles the data eviction when the cache is full. When an item is requested from the cache, it may result in a miss, which means data needs to be fetched from the database and the cache needs to be updated. But before doing that, an item needs to be removed. The following section describes several strategies on how to choose which item to pick.
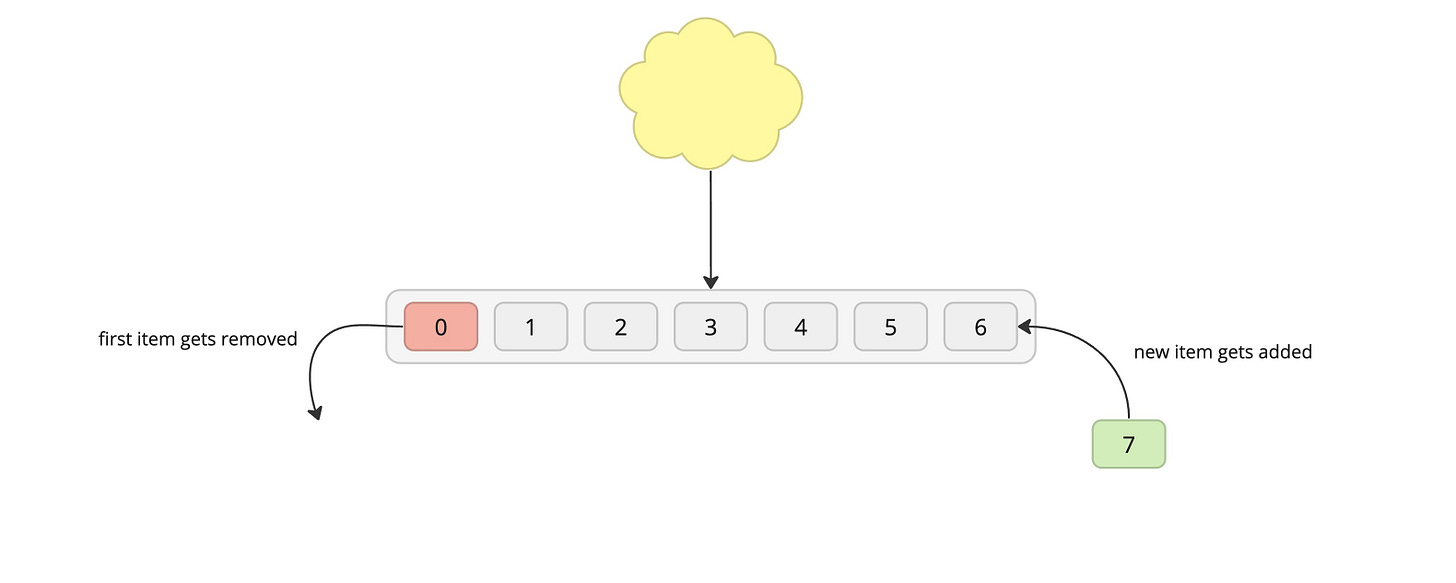
Queue-Based Policies
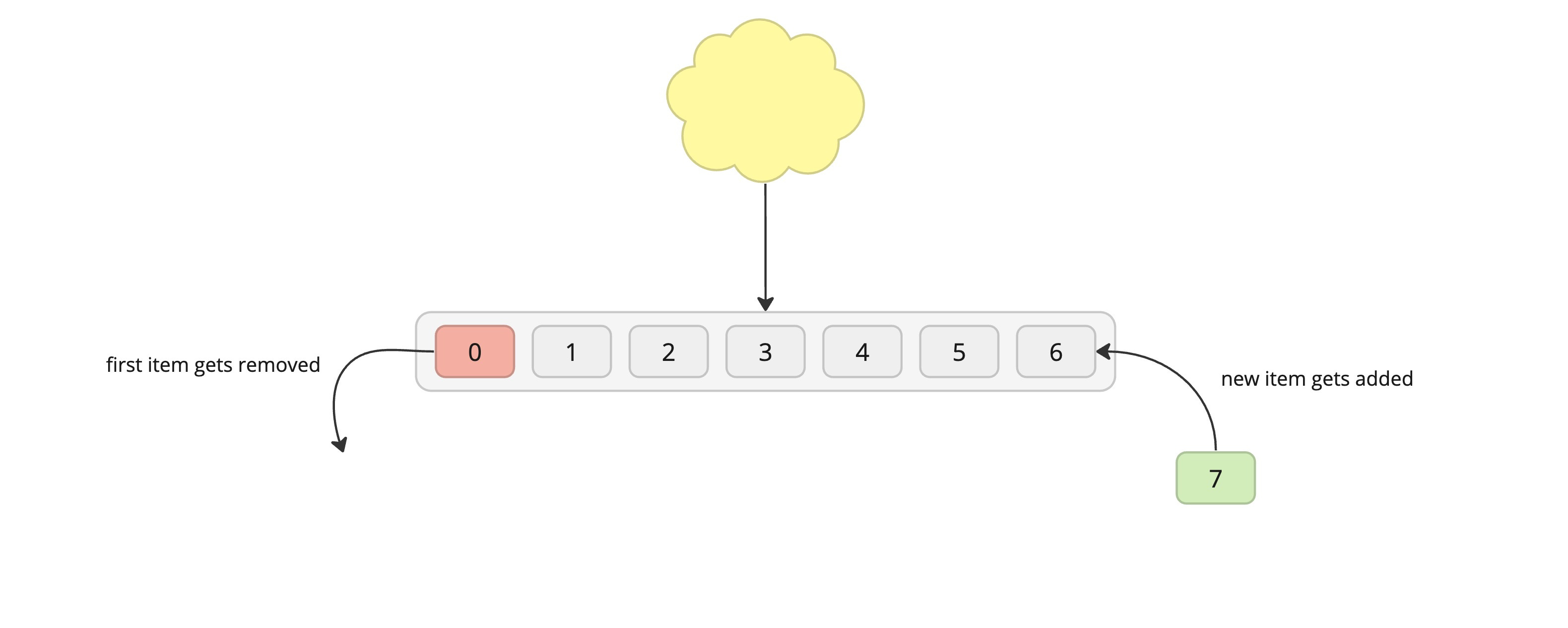
FIFO (First-In-First-Out)
Process: The first in/oldest item gets removed to make space for the new item, which is then added to the end.
Pros:
Simplicity: Very easy to implement and understand.
Fairness (Of Sorts): Prevents any item from 'hogging' the cache indefinitely if there's a steady stream of new data.
Cons:
Inefficient for Many Workloads: Real-world data access patterns often aren't purely FIFO order. An item used constantly might get evicted simply because it was added a while ago, leading to repetitive refetches of the same thing.
Ignores Popularity: A popular item accessed right after eviction will need to be fetched again, even though there may be other rarely-used data in the cache.
Data eviction following a FIFO approach LIFO (Last-In-First-Out)
Process: The last in/newest item gets removed to make space for the new item, which is then added to the end.
Pros: Same as FIFO
Cons: Same as FIFO
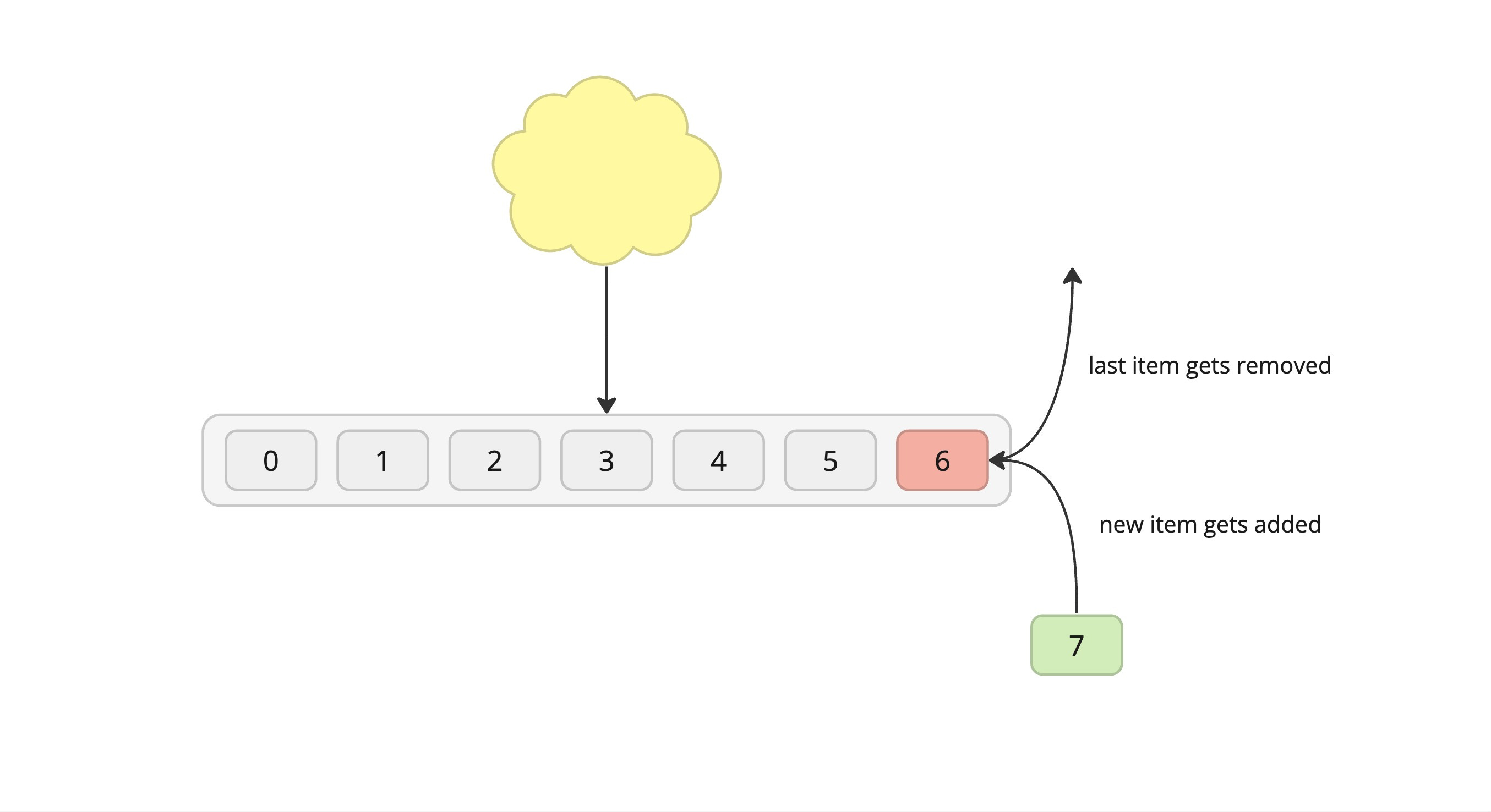
Recency-Based Policies
LRU (Least Recently Used)
Process: The basic principle of LRU caching is to remove the least recently used items first when the cache reaches its capacity limit. This means that the cache keeps track of the order in which items are accessed, and when it needs to make space for a new item, it removes the least recently accessed item.
Pros:
Effective use of cache space: LRU caching maximizes the utilization of cache space by keeping frequently accessed items in memory.
Good performance: LRU caching performs well in scenarios where there is a high degree of temporal locality, such as web servers and databases.
Simple implementation: The basic LRU caching algorithm is relatively simple to implement and understand.
Cons:
Overhead: LRU caching requires additional data structures to keep track of access history, which can introduce overhead in terms of memory and computational resources.
Not suitable for all access patterns: LRU caching may not perform optimally in scenarios with non-temporal access patterns or where access frequencies vary widely.
Possible implementation:
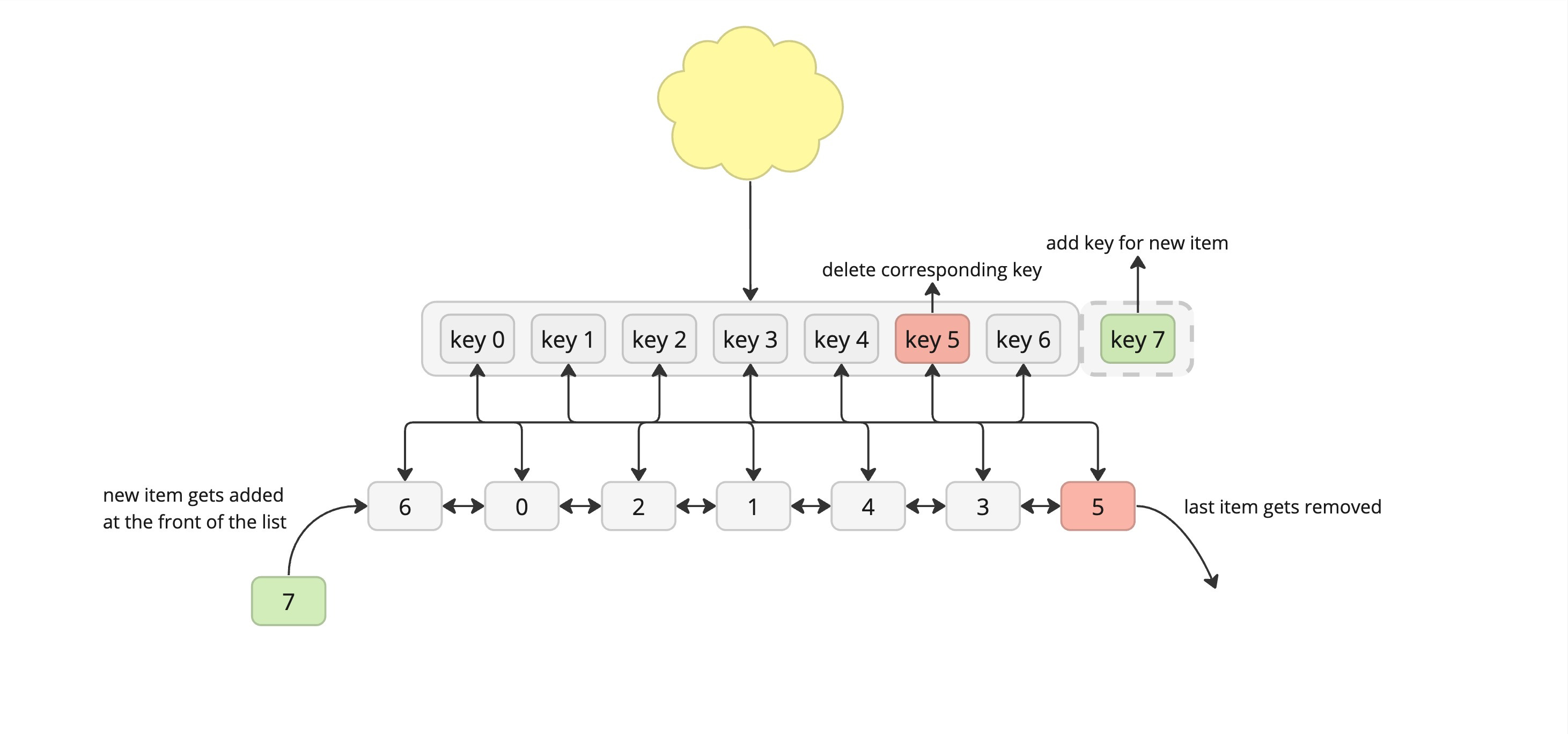
An LRU cache is often implemented by pairing a doubly linked list with a hash map. The linked list is set up with the most-recently used item at the head of the list and the least-recently used item at the tail.
When we get a request, we first look up the item in our hash map:
if it’s there, it’s a cache hit:
we use the hash map to quickly find the corresponding linked list node.
we then move the item's linked list node to the head of the linked list, since it's now the most recently used (so it shouldn't get evicted any time soon).
if it’s not there, it’s a cache miss:
if the cache is full - we evit the least recently used item which should be at the end of the queue.
we create a new linked list node and add it at the head of the queue and update the hashmap where the value points to the node we’ve just inserted.
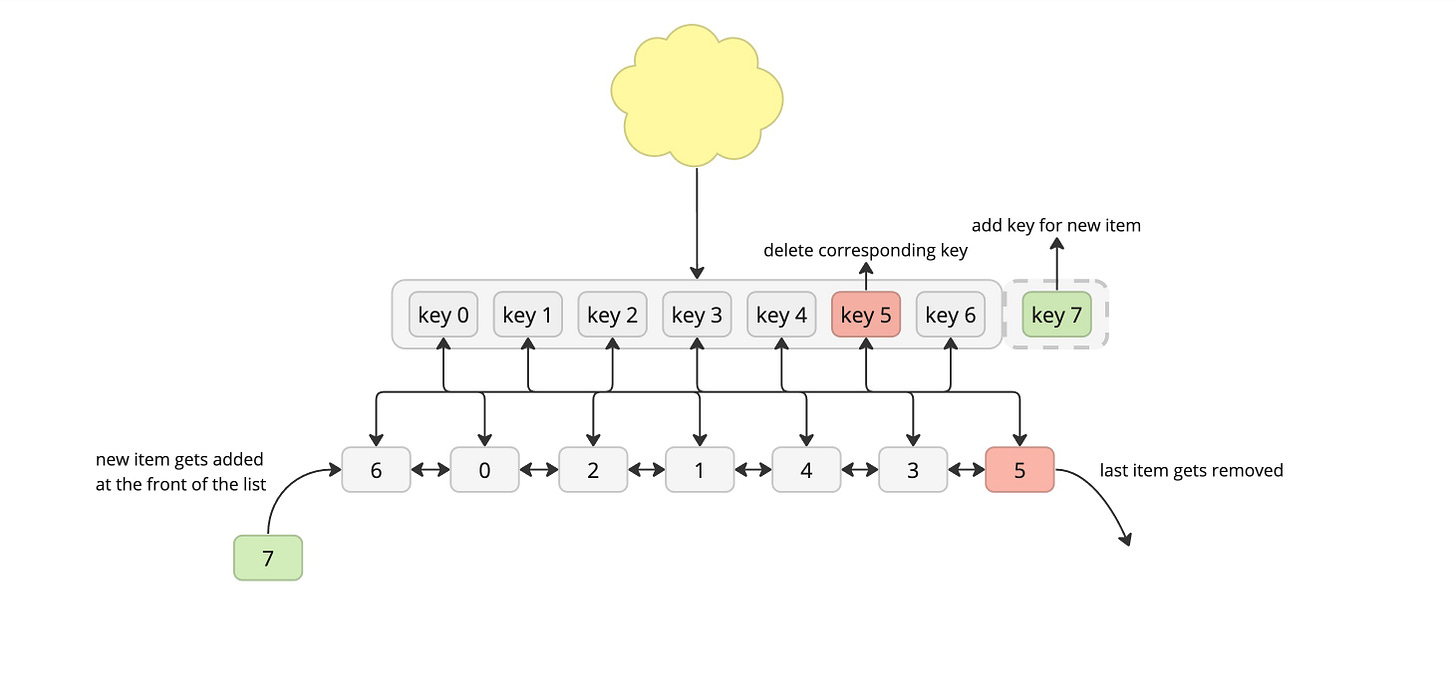
Data eviction following a LRU approach MRU (Most Recently Used)
Process: evicts the most recently accessed data item from the cache. When a new item needs to be added to the cache and it's already at full capacity, the cache algorithm looks at the usage history of the items and evicts the most recently used one. This makes room for the new item to be added. MRU can be useful in scenarios where a small subset of items is accessed frequently.
Pros: Same as LRU
Cons: Same as LRU
Frequency-Based Policies
LFU (Least Frequently Used)
Process: The basic principle of LFU caching is to remove the least frequently used items first when the cache reaches its capacity limit. This means that the cache keeps track of the frequency with which each item is accessed, and when it needs to make space for a new item, it removes the item that has been accessed the least frequently.
Pros:
Effective use of cache space: LFU caching maximizes the utilization of cache space by keeping frequently accessed items in memory.
Good performance: LFU caching performs well in scenarios where there are consistent access patterns and certain items are accessed more frequently than others.
Adaptive: LFU caching dynamically adjusts to changes in access patterns, ensuring that frequently accessed items remain in the cache.
Cons:
Complexity: LFU caching algorithms can be more complex to implement and maintain compared to simpler caching strategies like LRU (Least Recently Used).
Overhead: LFU caching requires additional data structures to track the access frequency of items, which can introduce overhead in terms of memory and computational resources.
Sensitivity to outliers: LFU caching may not perform optimally in scenarios with highly variable access patterns or sudden spikes in access frequency. Outliers in access frequency can skew the effectiveness of the cache.
Possible Implementation:
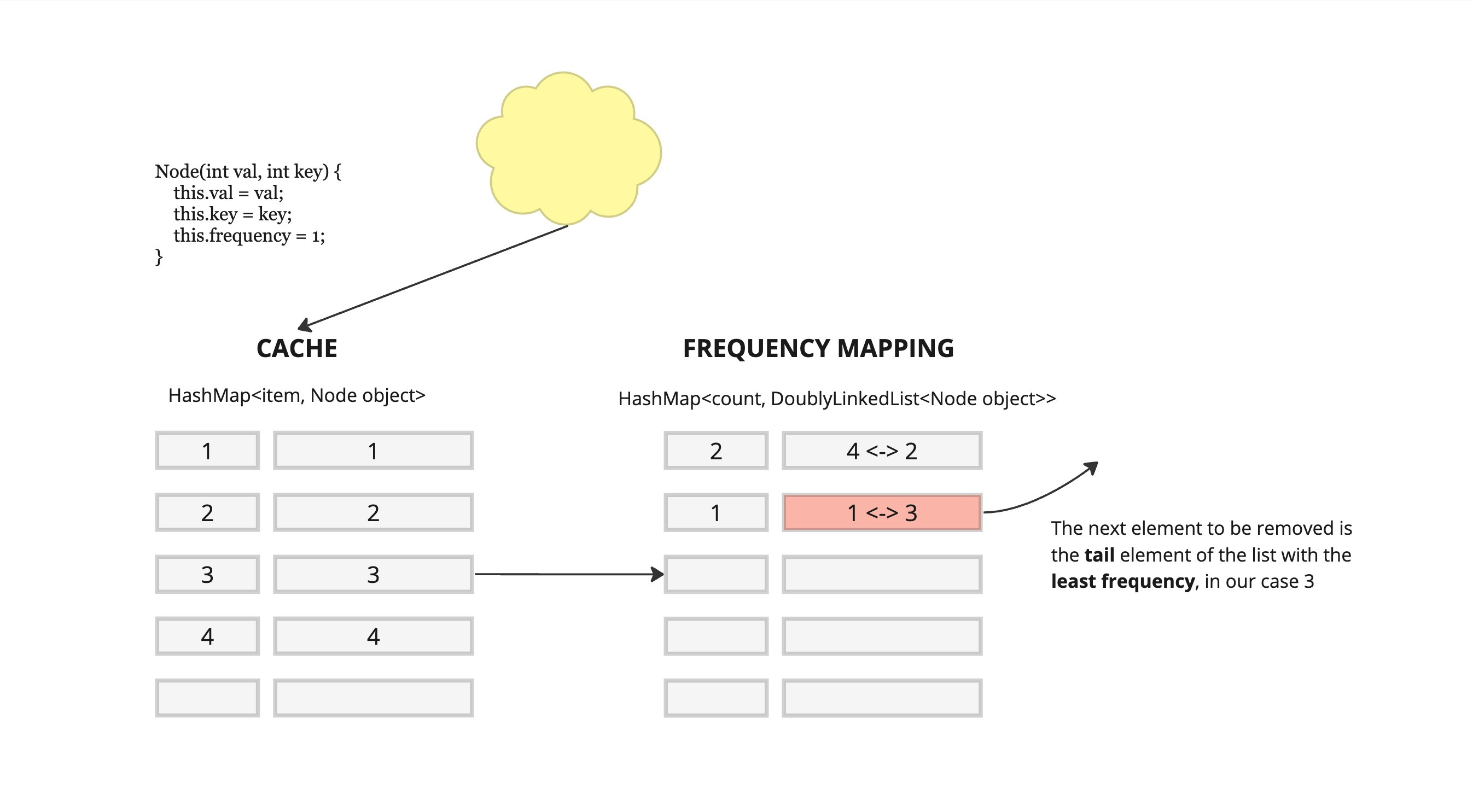
We are going to need 2 data structures, a cache map HashMap<item, Node> which holds our item along with a Node object
Node(int val, int key) {this.val = val;this.key = key;this.frequency = 1;}
and a frequency map HashMap<count, DoublyLinkedList<Node object>> which holds the count or frequency value a long with a list of all the items that have that given frequency.When the cache is full, the next element that needs to be removed is the tail element of the doubly linked list with the least frequency.
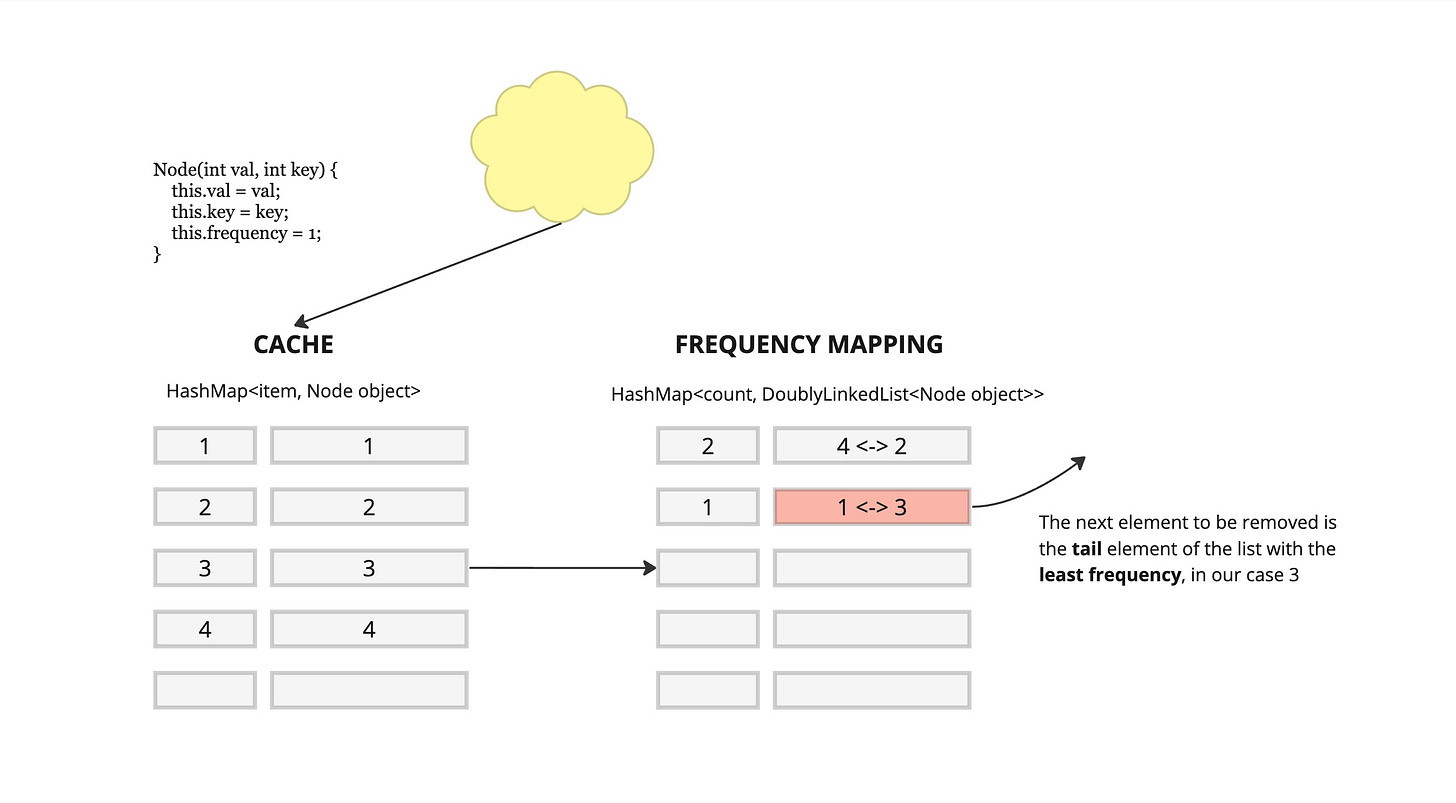
Data eviction following a LFU approach LFRU (Least Frequently Recently Used)
Process: based on a hybrid algorithm that combines aspects of both LFU (Least Frequently Used) and LRU (Least Recently Used) caching strategies. LFRU caching maintains both frequency and recency information for each item in the cache. It tracks how frequently an item is accessed (similar to LFU) and how recently it was accessed (similar to LRU). When a new item needs to be added to the cache and it's already at full capacity, the cache algorithm uses a combination of frequency and recency information to decide which item to evict.
If an item has a low frequency of access but was accessed recently, it may be considered valuable and kept in the cache.
If an item has a high frequency of access but hasn't been accessed recently, it may be considered less valuable and evicted from the cache.
Pros:
Balance: LFRU caching strikes a balance between considering both frequency and recency of access, leading to more nuanced cache management decisions.
Adaptability: LFRU caching adapts well to varying access patterns and workload changes, ensuring efficient use of cache space.
Performance: LFRU caching can provide good performance by retaining frequently accessed items while also accommodating recent access patterns.
Cons:
Complexity: LFRU caching algorithms can be complex to implement and may require additional computational overhead compared to simpler caching strategies.
Resource Consumption: Maintaining both frequency and recency information for each item in the cache may consume more memory and computational resources.
Tuning: Tuning the parameters of an LFRU caching algorithm to optimize performance may require careful experimentation and analysis.
Cache Invalidation
Cache invalidation is the process of removing or marking as invalid data in a cache system. Implementing effective cache invalidation strategies is vital for preserving data integrity and preventing the delivery of stale or obsolete data.
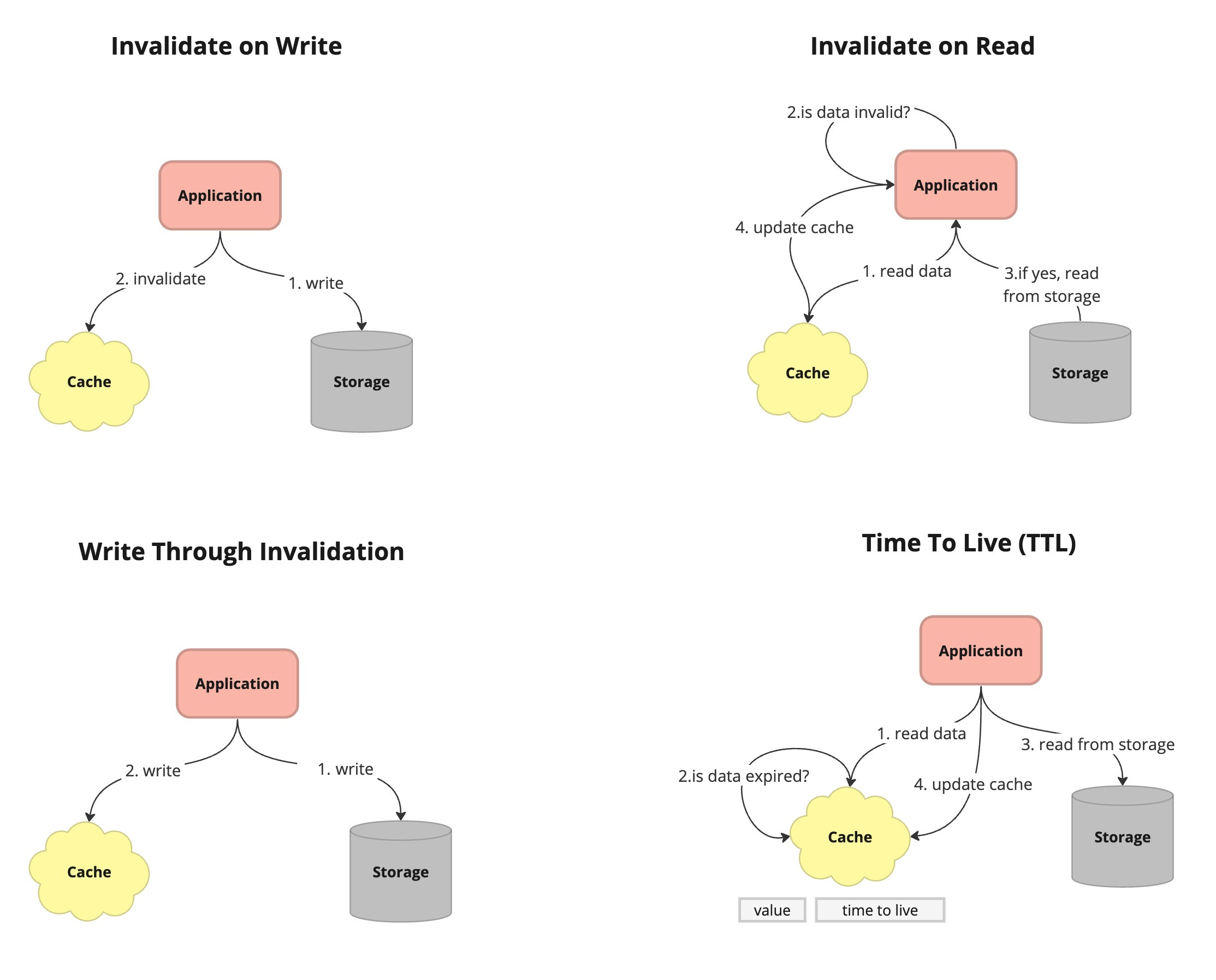
Invalidating on Write
This cache invalidation happens upon modifications to the underlying data source. Whenever a modification operation, like an update or deletion, takes place, the cache is notified or marked to invalidate the associated cached data. Subsequent attempts to access the invalidated data result in cache misses, prompting the retrieval of the latest information from the data source. While this method reduces the risk of serving outdated data, it may introduce a slight delay due to cache misses during the invalidation process.
Invalidating on Read
Cache invalidation occurs during data access or retrieval. When a read request is received, the cache verifies whether the cached data is still valid or has become outdated. If the data has expired or is marked as invalid, the cache retrieves the latest information from the data source and updates its contents before fulfilling the request. While this method ensures the delivery of up-to-date data, it introduces overhead to each read operation as the cache must confirm the freshness of the data before responding.
Write-Through Invalidation
In systems where data is written directly to the cache and the source of truth simultaneously, cache entries are invalidated whenever data is written or updated in the source of truth.
Time Based Invalidation
Cached data is invalidated after a certain period of time has elapsed. For example, a web page cache may be configured to invalidate its content every hour to ensure that users see the most recent version of the page.
Time-to-Live (TTL)
Similar to time based invalidation, TTL associates a time duration with each cached item. When an item is stored in the cache, it is marked with a TTL value indicating how long the item is considered valid.
Caching Strategies
Read Strategies
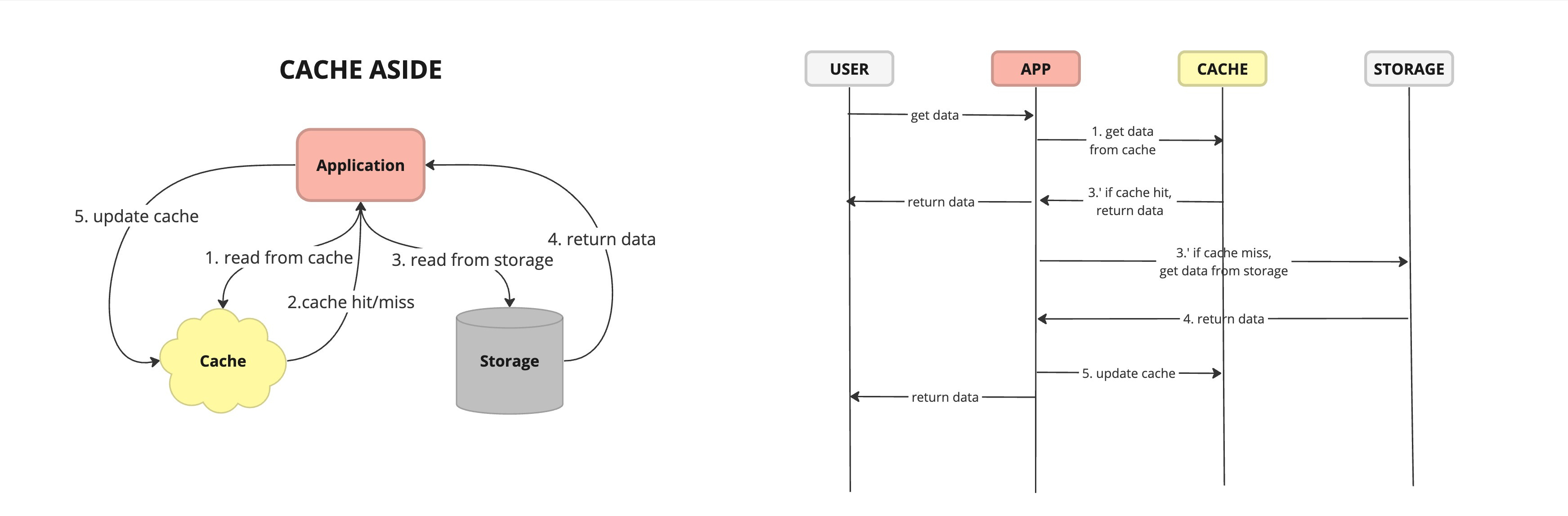
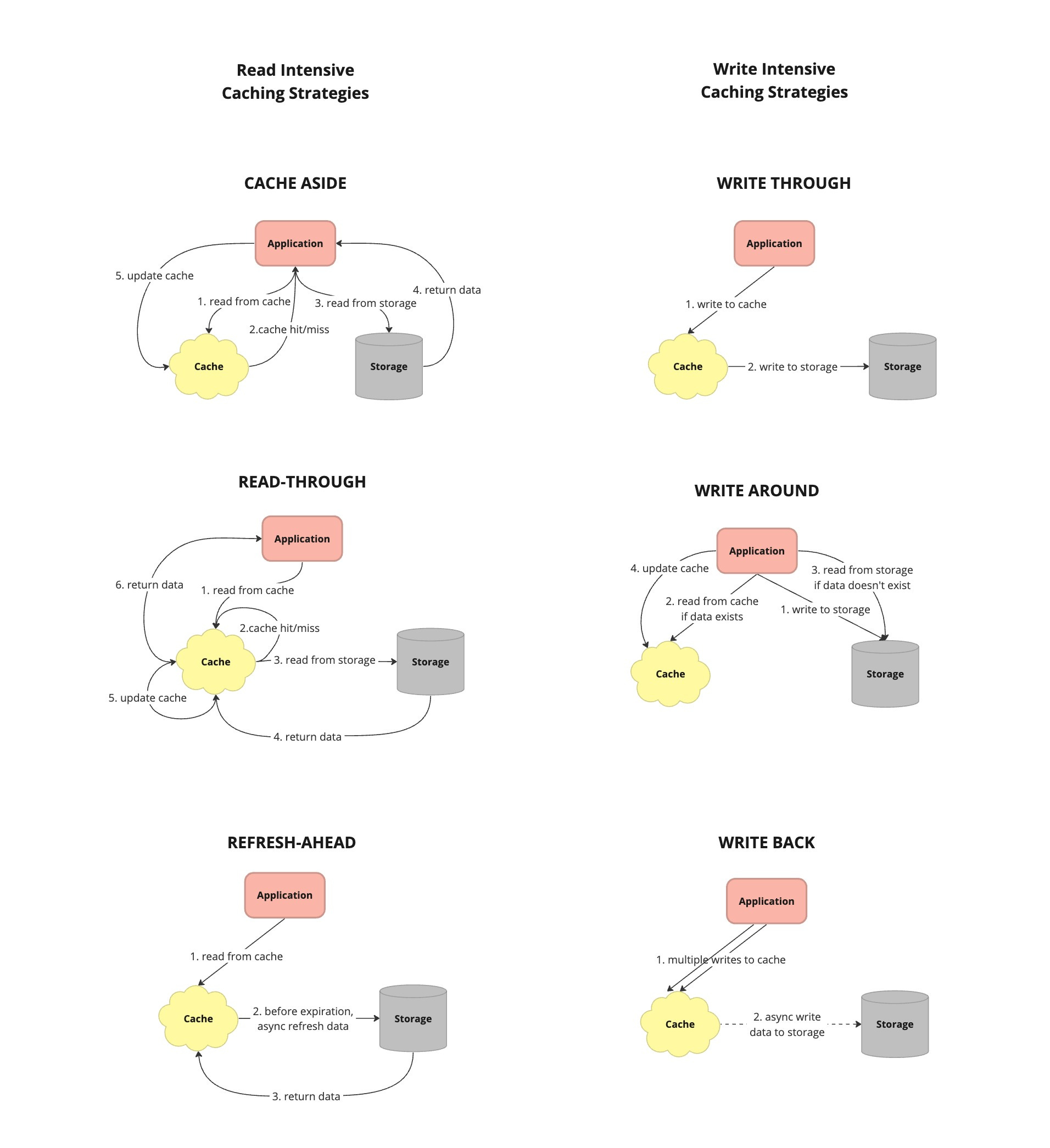
Cache Aside - also known as lazy loading or lazy population, is a caching strategy where the application is responsible for managing the cache directly. When data is requested, the application first checks the cache. If the data is found, it is returned from the cache. If the data is not in the cache, the application retrieves it from the data source, stores it in the cache, and then returns it to the caller.
Pros:
Flexibility: Cache-aside allows applications to cache data selectively, based on their specific requirements. This flexibility enables developers to optimize caching for performance and efficiency.
Control: Applications have full control over cache management, including when to populate, update, or evict cached data. This level of control allows for fine-tuning cache behavior to suit the application's needs.
Reduced Load: By caching frequently accessed data, cache-aside can reduce the load on the primary data source, leading to improved overall system performance and scalability.
Cons:
Stale Data: Without proactive cache population or expiration mechanisms, cache-aside may lead to serving stale or outdated data to users, particularly if data changes frequently in the primary data source.
Consistency Challenges: Ensuring consistency between the cache and the primary data source can be complex, particularly in scenarios involving distributed caching or multiple cache instances. Inconsistent data can lead to data integrity issues and user experience problems.
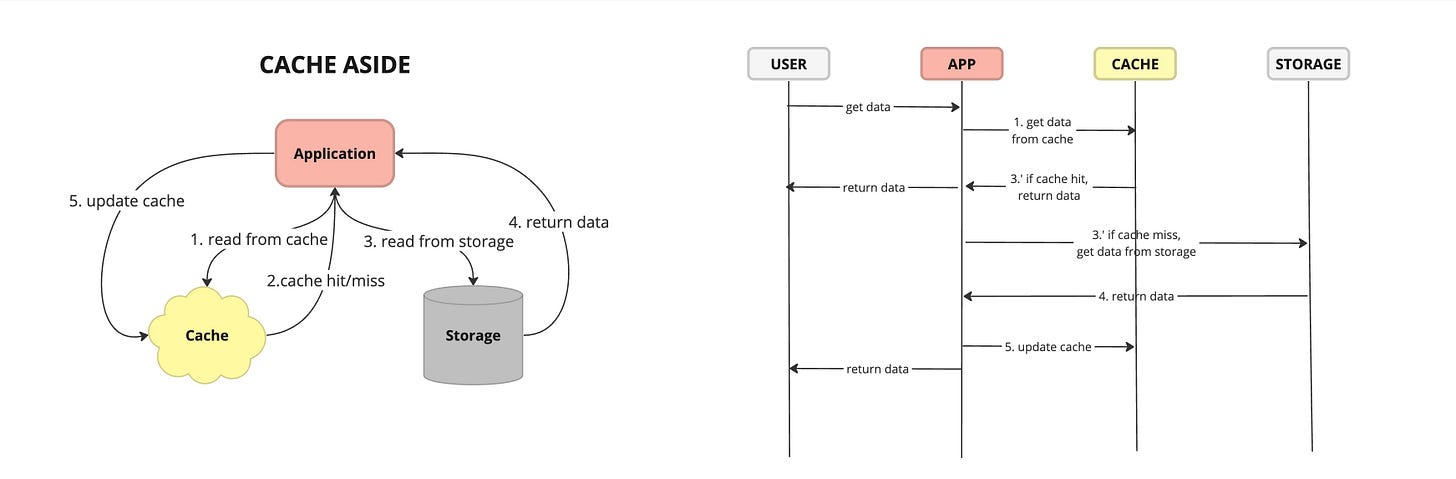
Cache Aside Flow Read Through - caching strategy where the application reads data from the cache, and if the requested data is not found in the cache (cache miss), the cache automatically fetches the data from the primary data source (such as a database) and populates the cache with the retrieved data before returning it to the application.
Pros:
Automatic Population: Cache read-through automatically populates the cache with requested data, reducing the need for explicit cache management.
Simplicity: Implementing cache read-through is relatively straightforward, as the caching logic is encapsulated within the cache itself, simplifying application code.
Cons:
Complexity in Eviction: Managing cache eviction policies to make room for new data can be challenging, especially in scenarios with limited cache capacity or high data volatility.
Resource Consumption: Cache read-through can consume additional system resources, such as memory and network bandwidth, particularly during cache population operations.
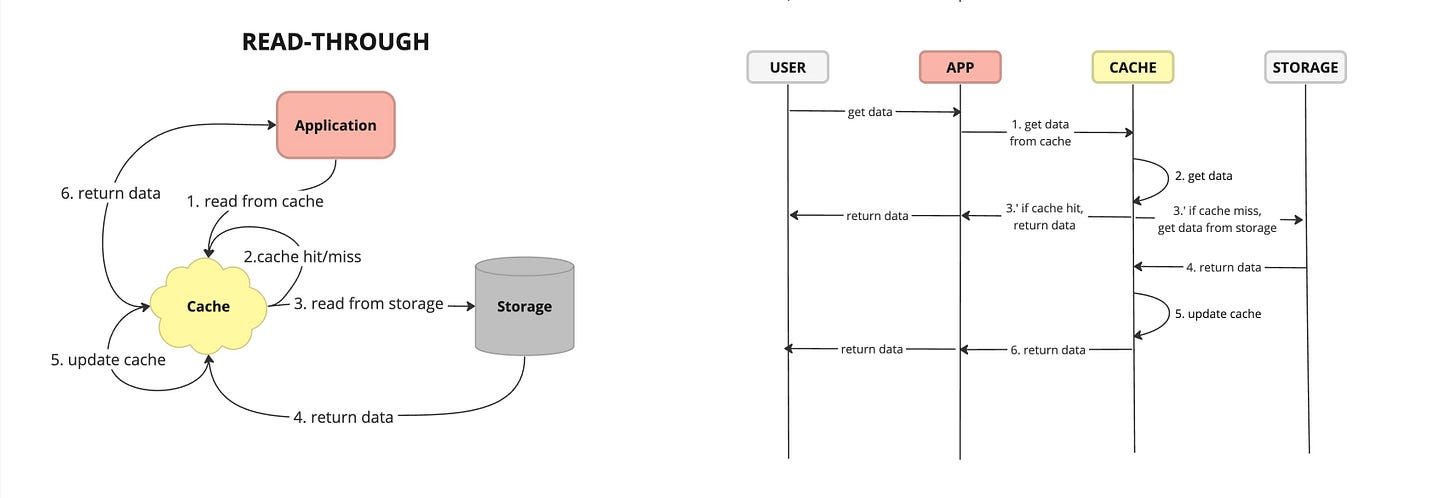
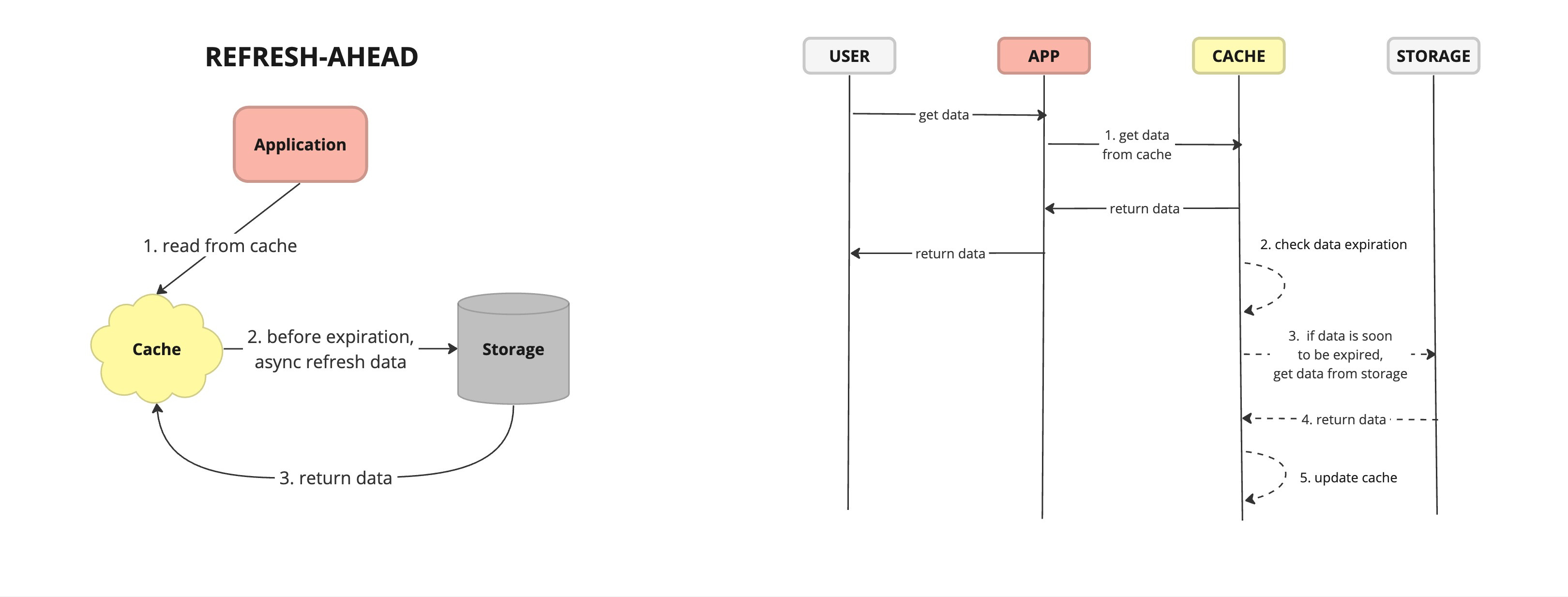
Cache Read Through Flow Refresh Ahead - also known as cache pre-loading or cache warm-up, is a caching strategy where the cache proactively fetches and stores data from the primary data source before it is requested by the application. This anticipatory approach aims to populate the cache with frequently accessed or critical data in advance, thereby reducing latency and improving overall system performance.
Pros:
Reduced Latency: By pre-loading frequently accessed data into the cache, cache refresh-ahead reduces the latency associated with fetching data from the primary source on demand.
Improved Performance: Proactively populating the cache with data that is likely to be accessed soon improves overall system performance by ensuring that frequently accessed data is readily available in memory.
Consistency: By periodically refreshing pre-loaded data, cache refresh-ahead helps maintain data consistency between the cache and the primary data source, ensuring that cached data remains up-to-date.
Cons:
Resource Overhead: Proactive data fetching and cache pre-loading consume additional system resources, such as memory, CPU, and network bandwidth, especially for large or frequently updated data sets.
Over-Population: Inefficient cache pre-loading strategies may lead to over-population of the cache with unnecessary or infrequently accessed data, resulting in wasted resources and reduced cache effectiveness.
Write Strategies
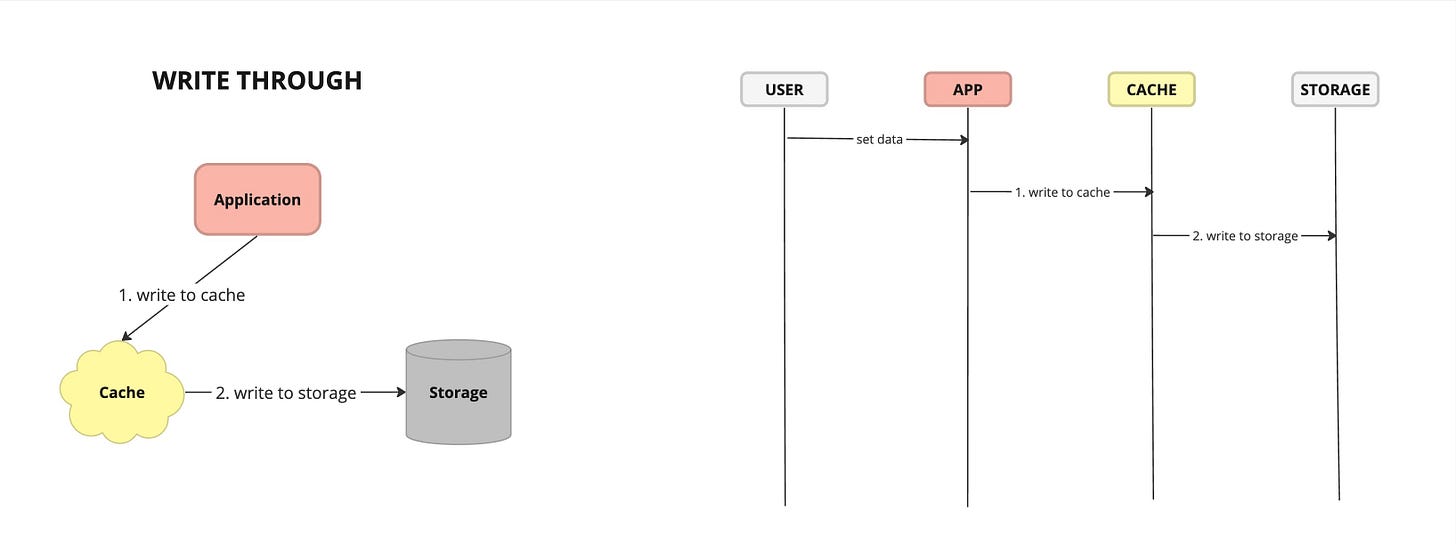
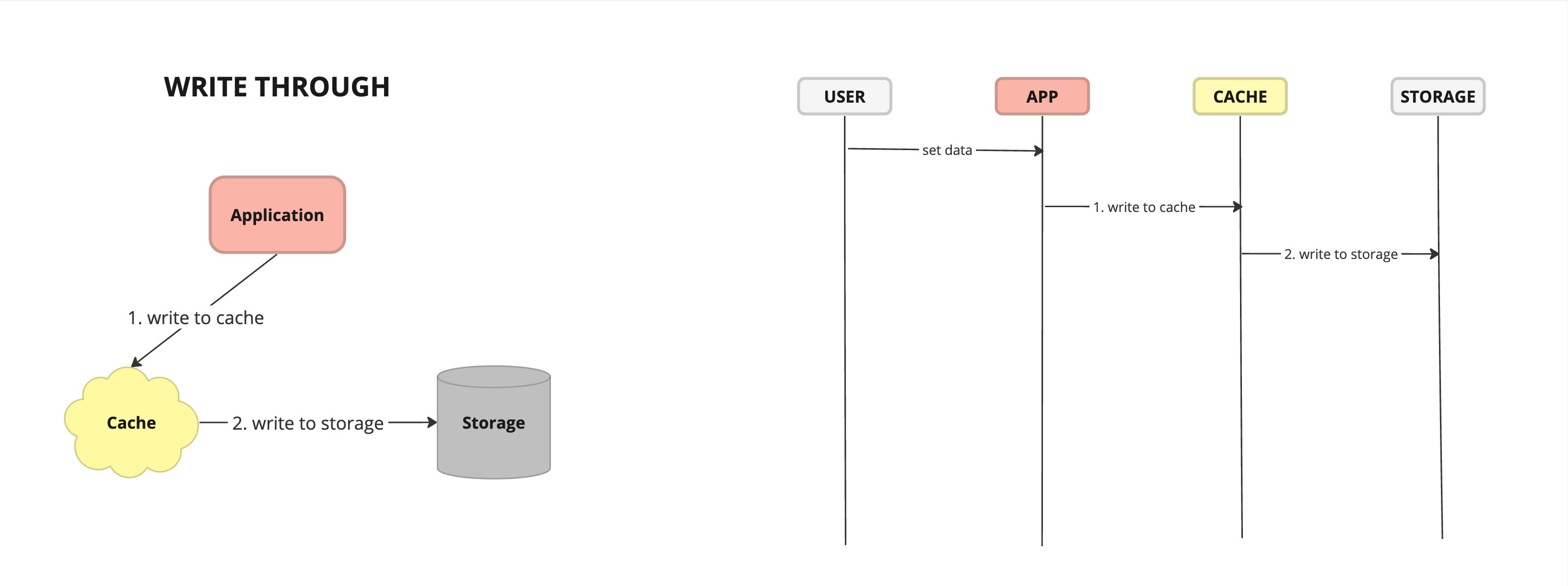
Write Through - caching strategy where data is written to both the cache and the underlying data store simultaneously whenever a write operation occurs.
Pros:
Data Consistency: By writing data to both the cache and the underlying data store simultaneously, cache write-through ensures that the cache remains synchronized with the primary data source, minimizing the risk of data inconsistency.
Simplicity: Cache write-through simplifies cache management by eliminating the need for separate cache invalidation or synchronization mechanisms, as data is always written to both the cache and the data store.
Cons:
Write Latency: Write operations in cache write-through may experience increased latency due to the additional step of writing data to both the cache and the data store, which can impact application performance, especially for write-heavy workloads.
Potential Bottleneck: In highly concurrent or distributed environments, cache write-through may introduce a potential bottleneck if multiple write operations contend for access to the cache and the data store simultaneously, leading to contention and performance degradation.
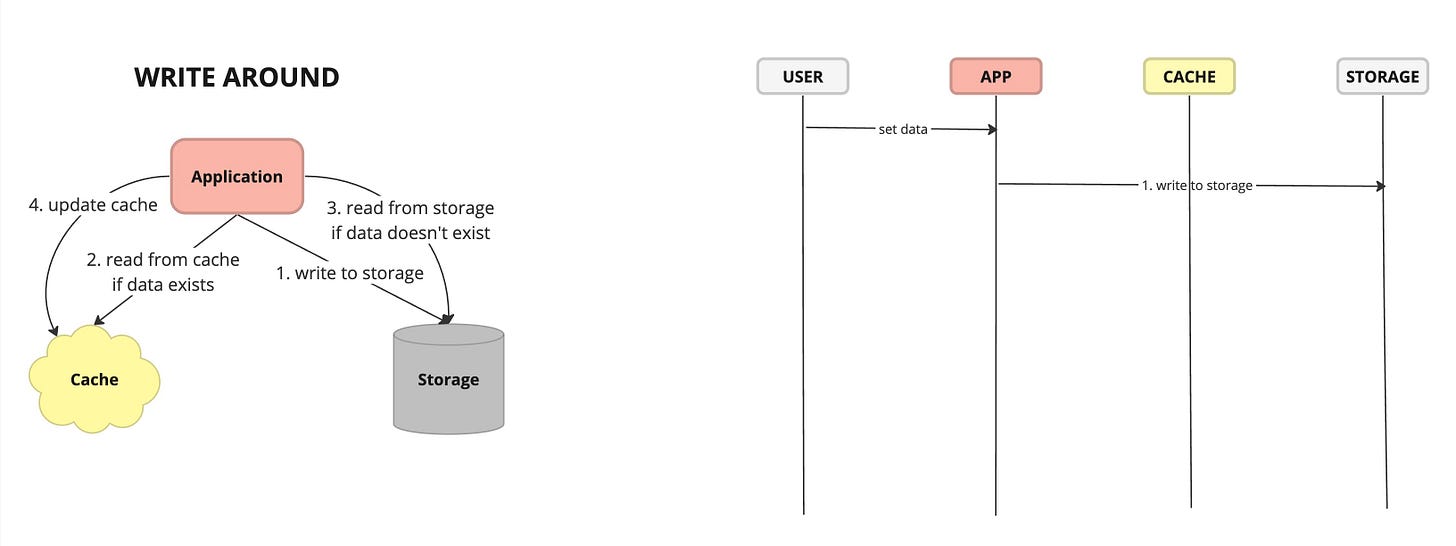
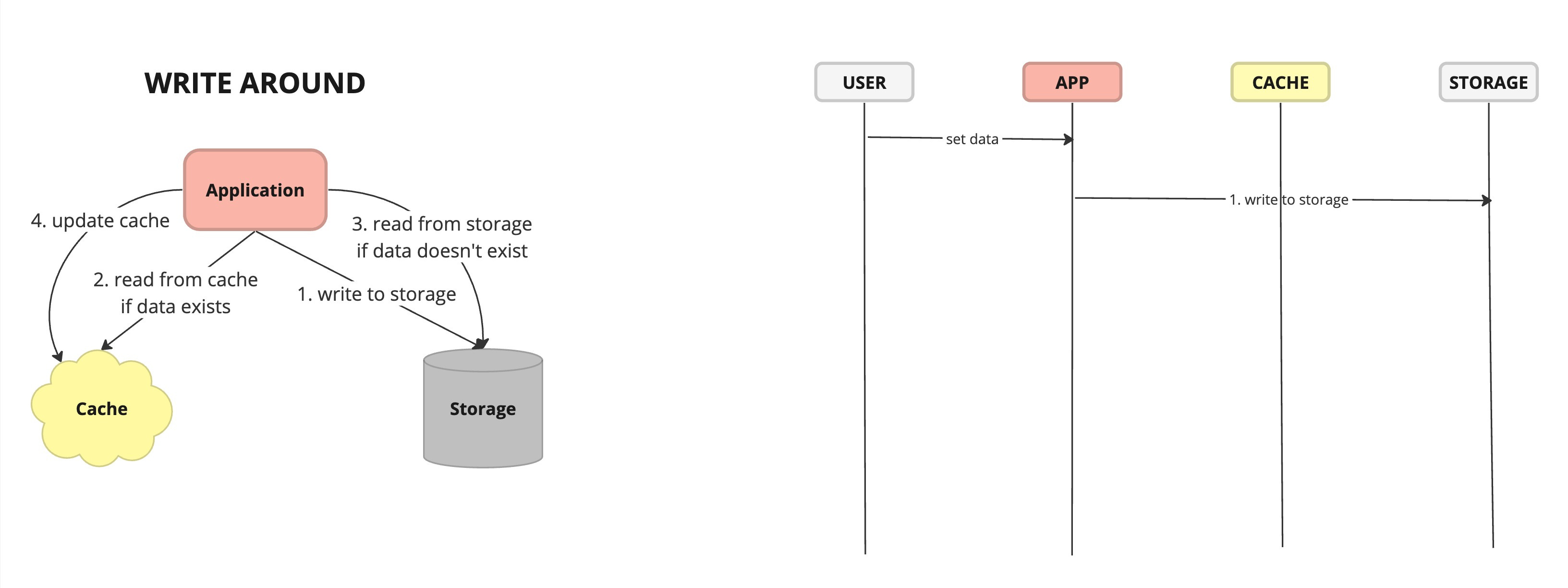
Cache Write Through Flow Write Around - caching strategy where write operations bypass the cache and are written directly to the underlying data store. Data is cached when it is read from the data store, allowing the cache to store frequently accessed data while avoiding unnecessary caching of infrequently accessed or transient data.
Pros:
Reduced Cache Pollution: By bypassing the cache for write operations, cache write-around avoids caching infrequently accessed or transient data, reducing cache pollution
Scalability: Cache write-around is well-suited for scenarios with write-heavy workloads or large datasets, as it minimizes the impact on cache performance and storage capacity by avoiding unnecessary caching of write operations.
Cons:
Read Latency: The first read operation for data that has not been cached incurs additional latency, as the data must be fetched from the underlying data store instead of the cache, potentially impacting application performance.
Stale Data: If data is frequently updated or modified in the underlying data store, cache write-around may result in cached data becoming stale, as the cache does not proactively invalidate or update cached data based on write operations.
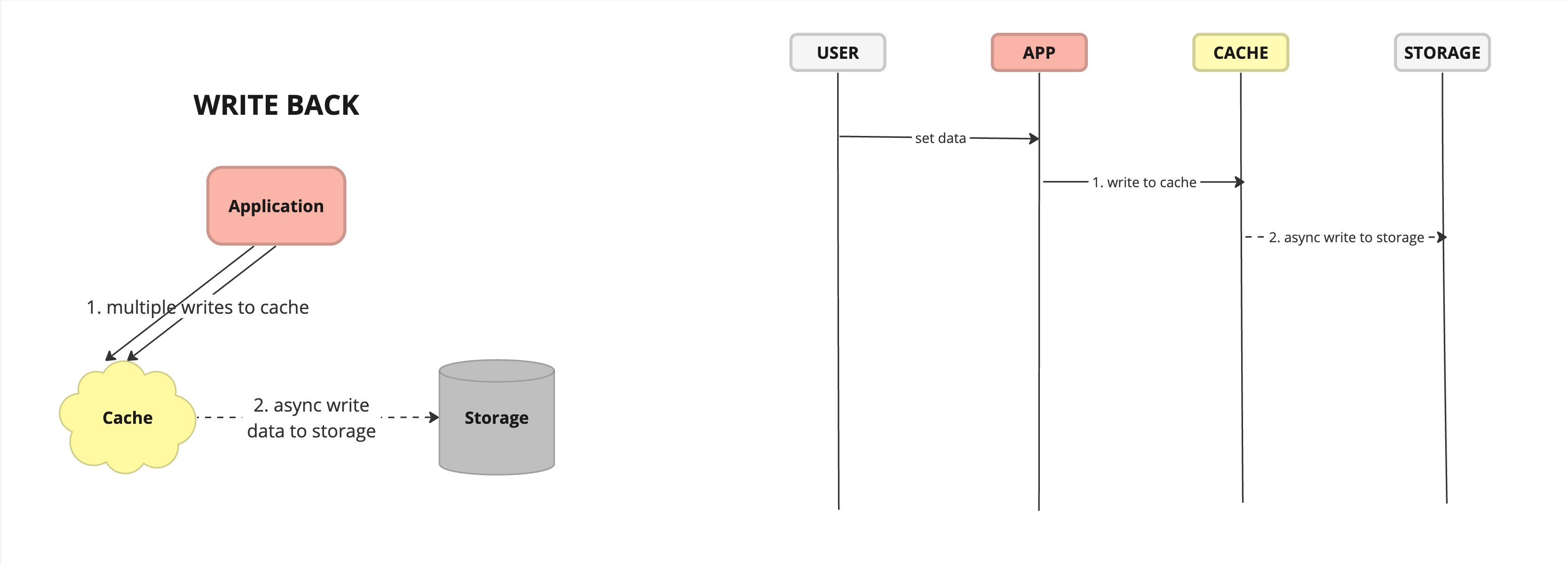
Cache Around Write Flow Write Back - caching strategy where write operations are initially written to the cache and later asynchronously propagated to the underlying data store.
Pros:
Improved Write Performance: Cache write-back improves write performance by acknowledging write operations as soon as they are written to the cache, without waiting for them to be persisted to the data store. This reduces latency and improves throughput, especially for write-heavy workloads.
Optimized Resource Utilization: Cache write-back optimizes resource utilization by buffering write operations in the cache, allowing the data store to handle write operations more efficiently and effectively, especially during peak load periods.
Cons:
Increased Complexity: Implementing cache write-back requires additional mechanisms for asynchronous data propagation, periodic flushing, and handling of failure scenarios, increasing system complexity and maintenance overhead.
Potential Data Loss: In the event of cache failure or system crash, cached data that has not been flushed to the data store may be lost, leading to potential data loss or corruption. Proper backup and recovery mechanisms are required to mitigate this risk.
Each caching strategy has its own advantages and considerations, and the selection of an appropriate strategy depends on the specific requirements and characteristics of the system.
Summary
In this article, we've explored the fundamentals of caching, covering the core definition of caching, scenarios where it offers significant advantages, the importance of eviction policies (like LRU or MRU) to manage cache size, and strategies for invalidation to ensure your cache aligns with the primary data source. We also touched on the flow of data between the cache and your database for both read and write operations.
Stay Tuned! In upcoming articles, we'll dive deeper into:
Types of Caches: Exploring different caching mechanisms like in-memory, distributed, and CDN caching.
Deployment Strategies: Understanding how to integrate caching into your architecture.
Metrics: How to monitor cache performance for optimal results.
Implementation Solutions: Practical examples with popular caching tools and libraries.